
Tutorial 大规模预训练技术实战
本文为学习笔记,原始视频参考 Tutorial:大规模预训练技术实战
预训练语言模型
THUNLP 韩旭

背景
2018 年,以 ELMo 和 BERT 为代表的预训练语言模型带来了一场 NLP 领域的变革以预训练语言模型为骨干的工作在几乎所有 NLP 任务上取得了极大突破,各类 benchmarks的结果被不断推高。

预训练语言模型在 GLUE 上的结果超越人类水平,体现了语言理解能力。GLUE Benchmark
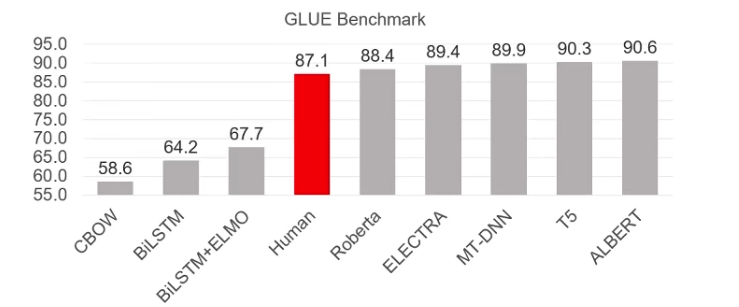
预训练语言模型在对话系统上也取得了突破,体现了语言生成能力
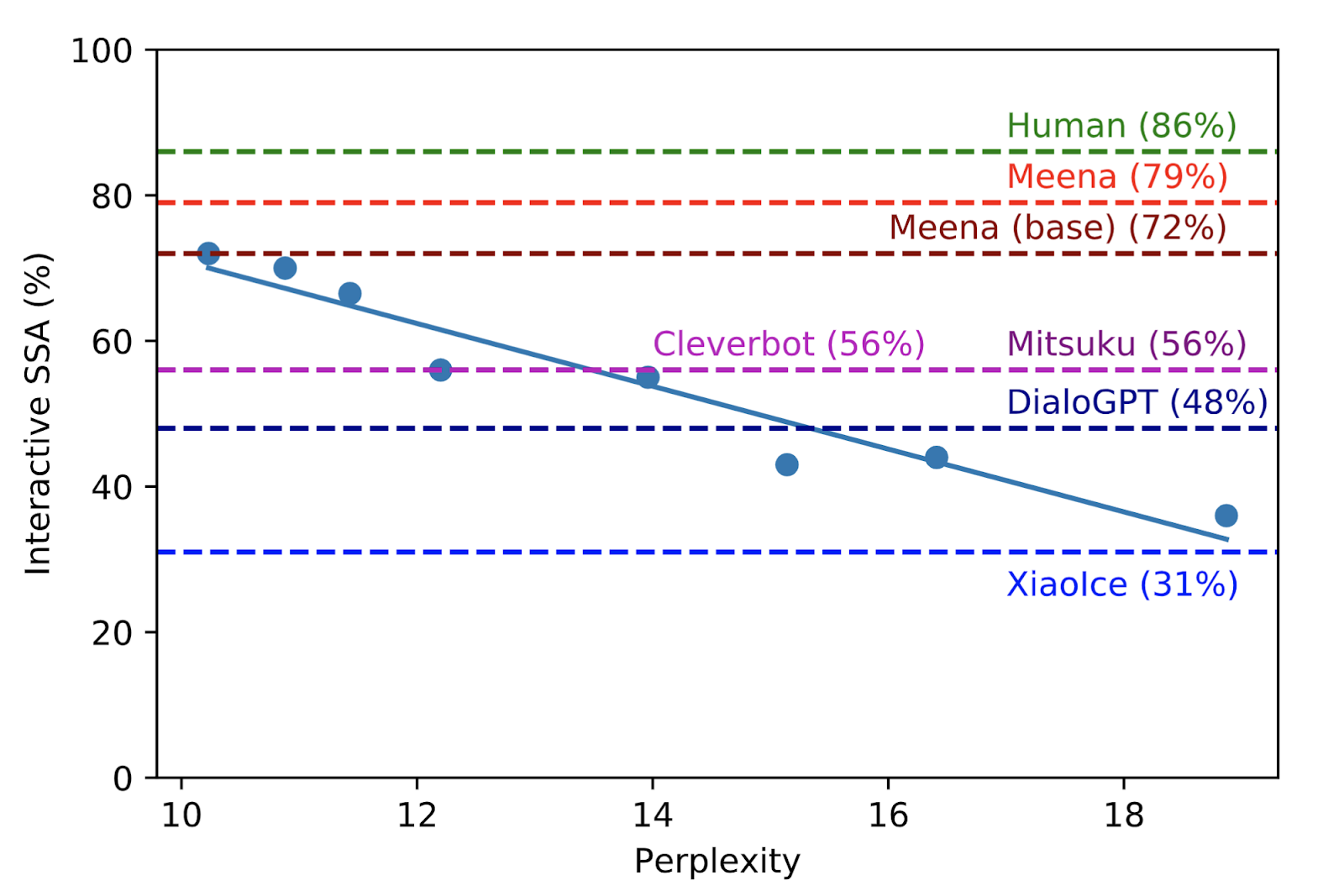
https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
2018年之后,预训练语言模型的三大特点:
- 参数量多
- 数据量大
- 计算量大
增大参数、增大数据是进一步提升性能的有效手段
预训练模型规模近两年来以每年约10倍的速度增长
数据量也相应在增长,计算代价也愈发高昂
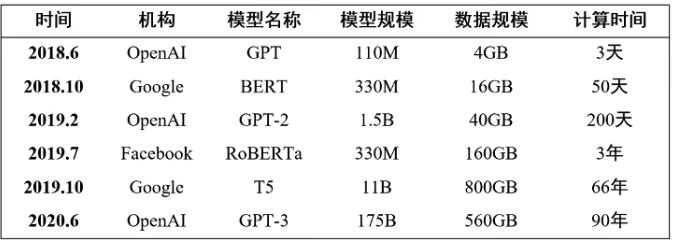
注:M-百万,B-十亿,最后一列计算时间为使用单块 NVIDIA V100 GPU 训练的估计时间
GPT-3 具备了一定的知识,并能进行一定程度上的推理

此外,GPT-3 具备了强大的零次/少次学习(Zero/Few-shot Learning)能力,能够执行诸多任务
采用预训练语言模型已是目前各类NLP 任务的标配。语言模型相关的研究在 2018 年后也增长极快。
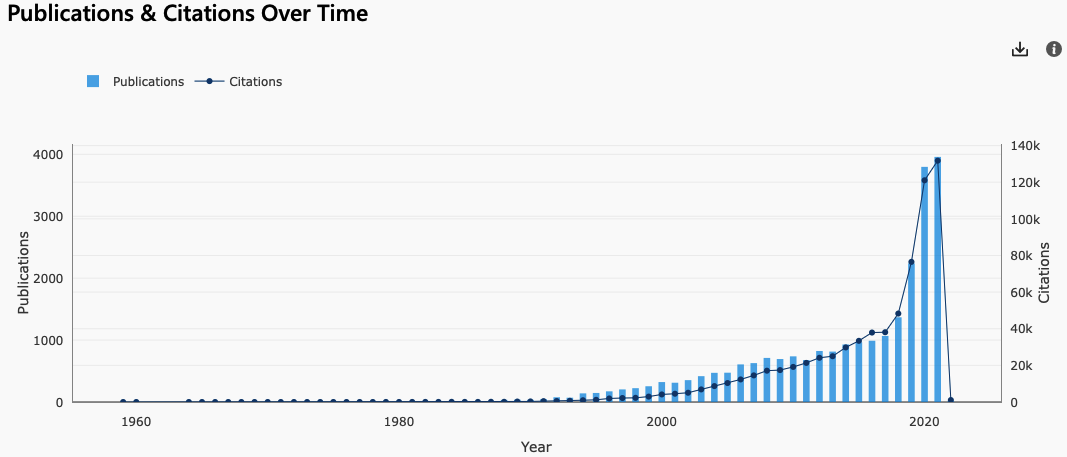
Microsoft Academic|Language model
迁移学习、自监督与预训练
深度学习是现有自然语言模型的主流框架,是实现自然语言处理典型任务的最好方法。面临挑战:缺少大规模有监督数据、模型深度有限、泛化性能较差
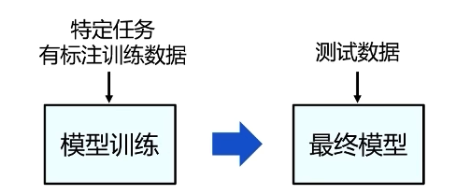
预训练语言模型基于大规模无标注文本,自动学习通用语言模式,泛化性能强,可用于多种下游任务
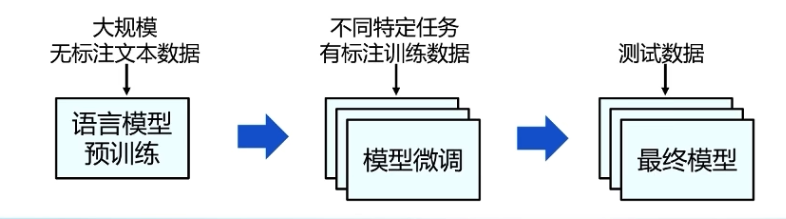
和迁移学习区别?
预训练与微调的基本范式可溯源到迁移学习,人类可以应用以前学到的知识来更快地解决新问题。
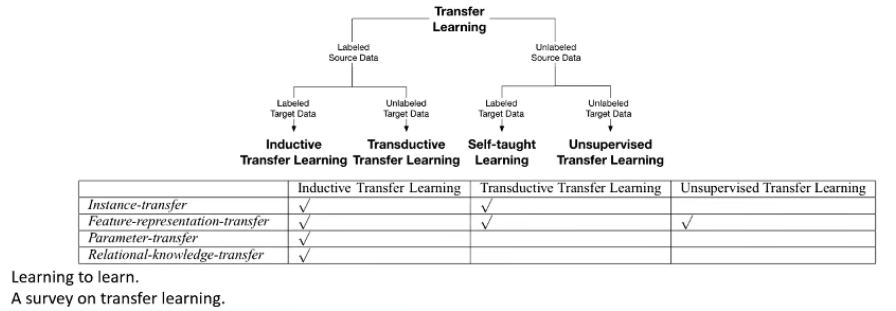
迁移学习采用了 “预训练-微调” 框架来实现 “知识获取-知识迁移”。在迁移方式上,feature-representation-transfer、parameter-transfer 基本囊括后续预训练模型的范式
基于知识迁移的预训练框架在CV上被使用
- 在大规模有监督数据 ImageNet 上进行预训练
- 在下游任务上微调
- 采用深层的卷积神经网络
比较典型的代表就是ResNet,ImageNet海量标注图片使得 ResNet 具备了优异的图片特征获取能力可以通过微调 ResNet, 有效支持下游任务
ResNet:Deep Residual Learning for Image Recognition
能否不使用标注数据来获取知识?挖掘数据内部信息作监督的自监督学习
对比学习
- 正例:同一张图片的不同处理结果,随机裁剪,颜色失真,随机高斯模糊等
- 负例:其他图片
如何度量文本的概率?
Pr(l like deep learning)>Pr(I hate deep learning)
自监督的词向量预训练,可以作为下游任务的输入
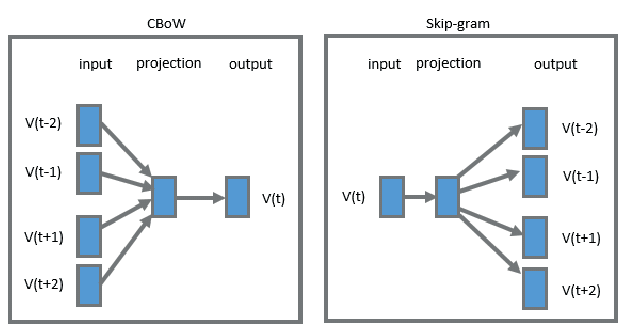
Efficient Estimation of Word Representations in Vector Space
预训练词向量的问题:
无法消歧
- I go to bank for money deposit.
- I go to bank for fishing.
无法区分反义词
- I love this movie.The movie is so bad.
- I don't love this movie.The movie is so good.
上下文相关的预训练词向量
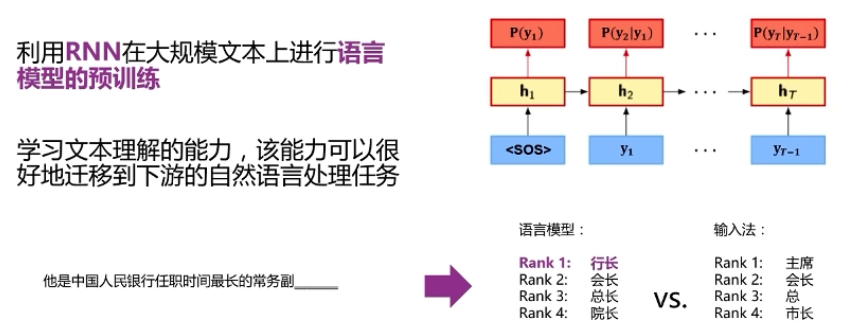
ELMo:Deep contextualized word representations
ULMFiT:Universal Language Model Fine-tuning for Text Classification
对比CV和NLP在早期预训练的路径
选择上,有两点不同:
- 监督 VS 自监督
- 深模型 VS 浅模型
NLP 深度模型的突破口 Transformer. 基于 Transformer, 衍生出一系列深度的预训练模型
Attention is All You Need|Transformer
经典案例
GPT
采用语言模型作为预训练任务 $P\left(x_{t} \mid x_{1}, x_{2}, \ldots, x_{t-1}\right)$
第一个采用 Transformer 进行预训练的模型,可以用在下游生成任务(作为 decoder)、语言理解任务上(作为 encoder)

Generative Pre-trained Transformer
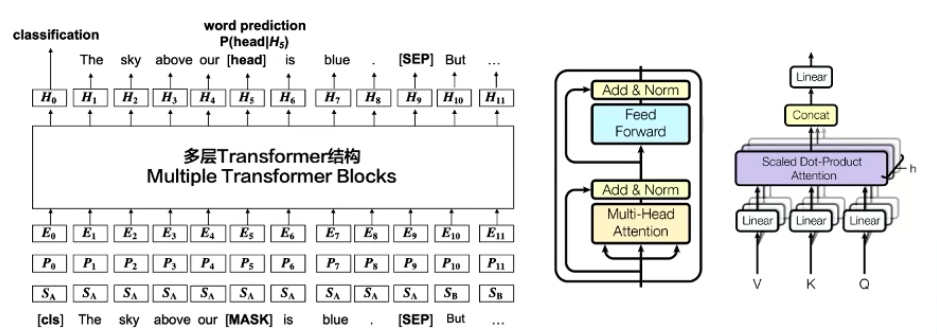
BERT
自监督的预训练任务
Masked language model (MLM)

Next sentence prediction (NSP,discourse-level)

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
RoBERTa
在 BERT 基础上
- 只用 MLM
- 不用 NSP
- 扩大训练数据量
- 扩大训练的 Batch Size
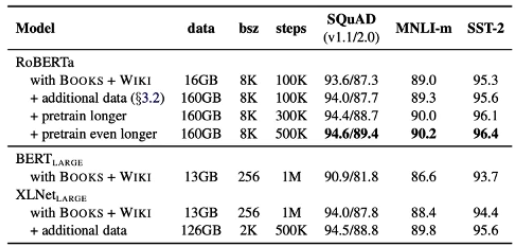
比 BERT 更稳定、效果更好
RoBERTa: A Robustly Optimized BERT Pretraining Approach
ALBERT
在BERT基础上
- 共享不同层的参数,减少参数量
- 性能不会有太大损失
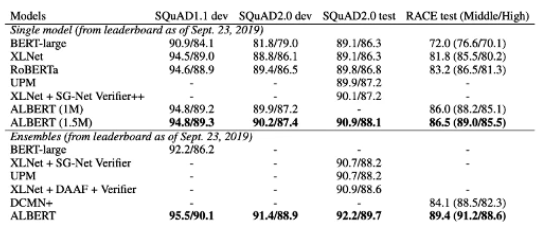
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ERNIE
在 BERT 基础上引入外部知识图谱信息增强模型对于专有名词的理解
在模型层面
- 模型分为文本编码层、知识信息的混
合编码层 - 混合编码层同时输入文本序列和实体序列进行处理,进行信息融合层
类似模型:K-BERT、KnowBERT
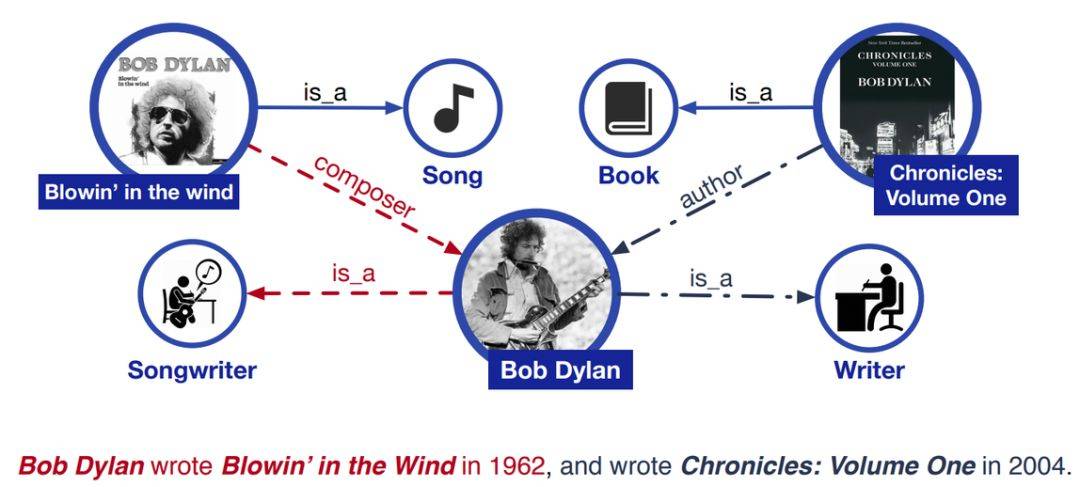
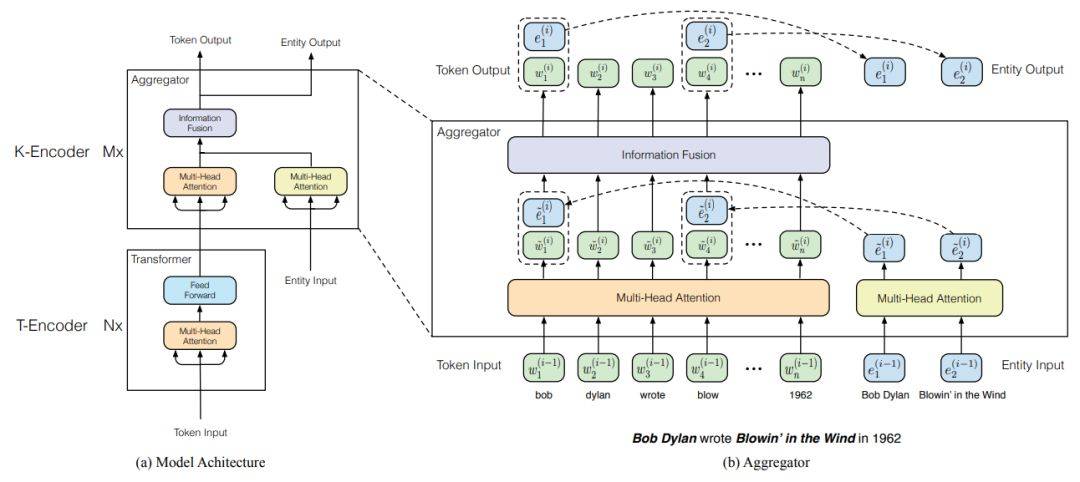
ERNIE: Enhanced Language Representation with Informative Entities
清华等提出ERNIE:知识图谱结合BERT才是“有文化”的语言模型 | 论文频道 | 领研网
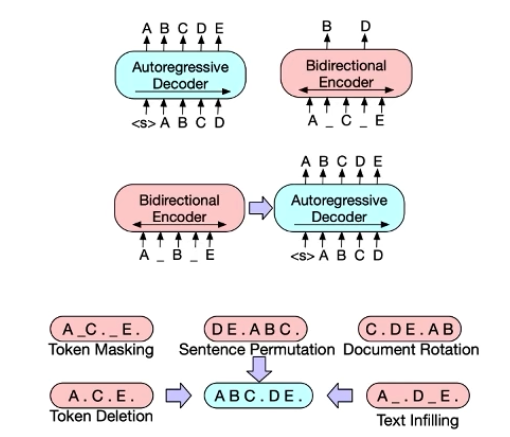
BART(Facebook)
自监督的预训练任务
- 用 Decoder: 来进行 MLM
- 遮蔽的方式包括遮盖、删除、乱序、旋转、填充
- 既解决文本理解任务、也解决文本生成任务
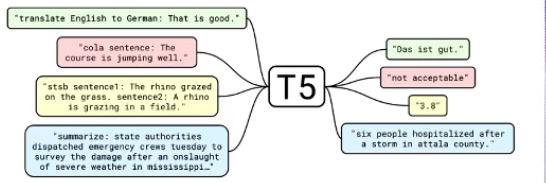
T5(Google)
自监督的预训练任务
- 用 Decoder 来进行 MLM
- 将下游不同任务统一为类似形式(生成),方便生成结果
- 基于海量数据 Colossal Clean Crawled Corpus (C4) 进行训练
- 较 BART 更为强悍
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Mixture of Expert (MoE)
MoE 旨在混合多个专家的处理能力,共同执行任务。类似模型融合
两种做法:
- Expert 为一个模型,例如 SVM、决策树或者神经网络
[1](MoE) - Expert 为一个子结构
[2](DMoE)
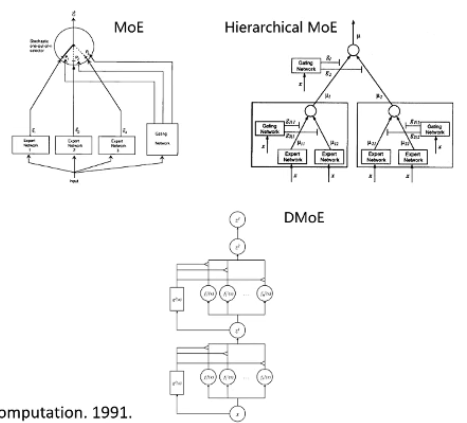
[1] Adaptive Mixtures of Local Expert.Jacobs et al.Neural Computation.1991.
[2] Learning Factored Representations in a Deep Mixture of Experts.Eigen etal.ICLR.2014.
MoE+LSTM(Google)
将 LSTM 中间的线性操作变为 MOE, 训练出干亿参数的 LSTM 模型
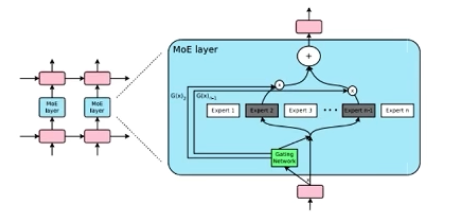
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Switch Transformers (Google)
在 Transformer 的线性层上采用 MOE 是当前低代价学习巨形模型的有效手段。MoE 的形式也方便计算机集群进行计算的负载均衡。参数量可到万亿级别。

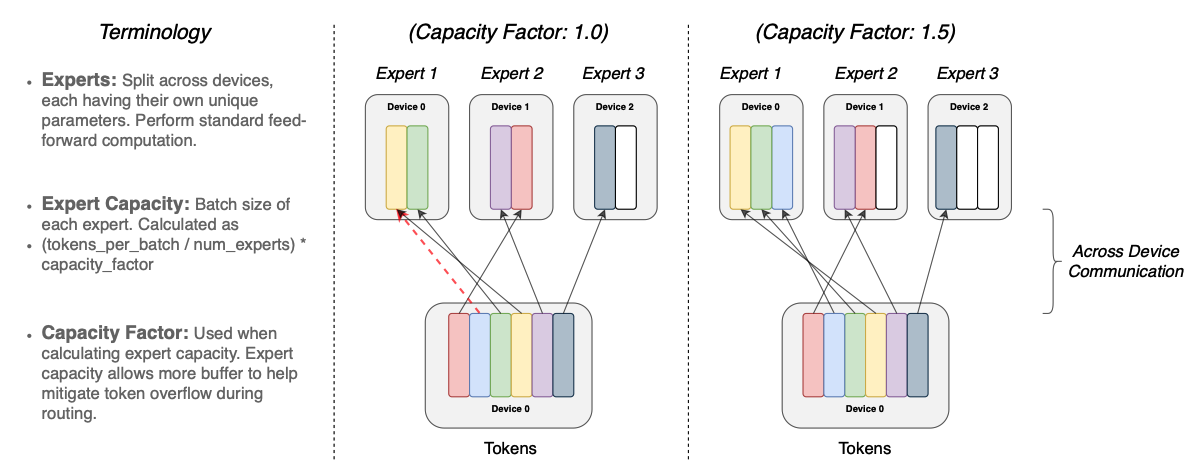
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
高效微调
Prompt Tuning
认为预训练模型足够聪明,实际中预训练模型不行,不是因为他不行,而是因为提问的不对。
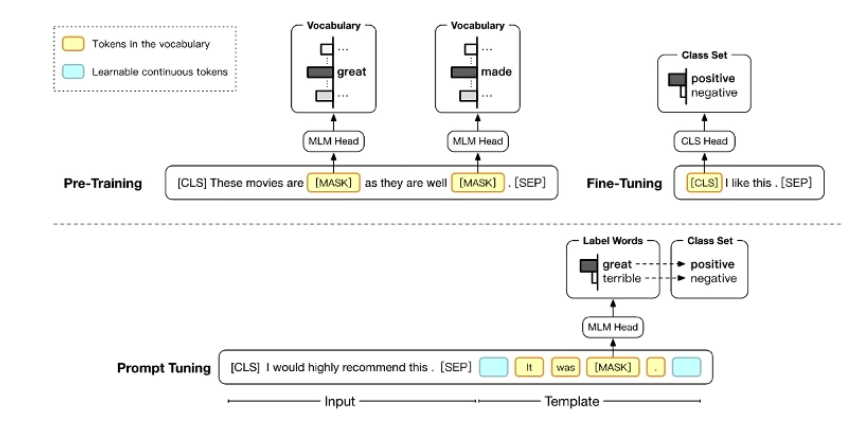
Pattern-Exploiting Training (PET)
- 人工定义多个模板,转化为 MLM 的问题,多个模板训出的模型之间 Ensemble
- 用 ensemble 的模型给无标注数据打标签,全参数 fine-tune
- 半监督场景下显著好于直接 fine-tune, 在 ALBERT 上面可以达到和 GPT-3 相似的性能
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
https://arxiv.org/abs/2009.07118
AUTOPROMPT
如何寻找更好的 prompt 来做 probing 任务。
- 在输入的句子后面拼上 prompt,
[MASK]位置预测 label 对应的词,转化为 MLM 任务 - 离散地优化 prompt, 和 label 对应的词,保证它们在词表中,模型参数 fix
- 在一些数据集的 low-resource 情况下好于 fine-tune
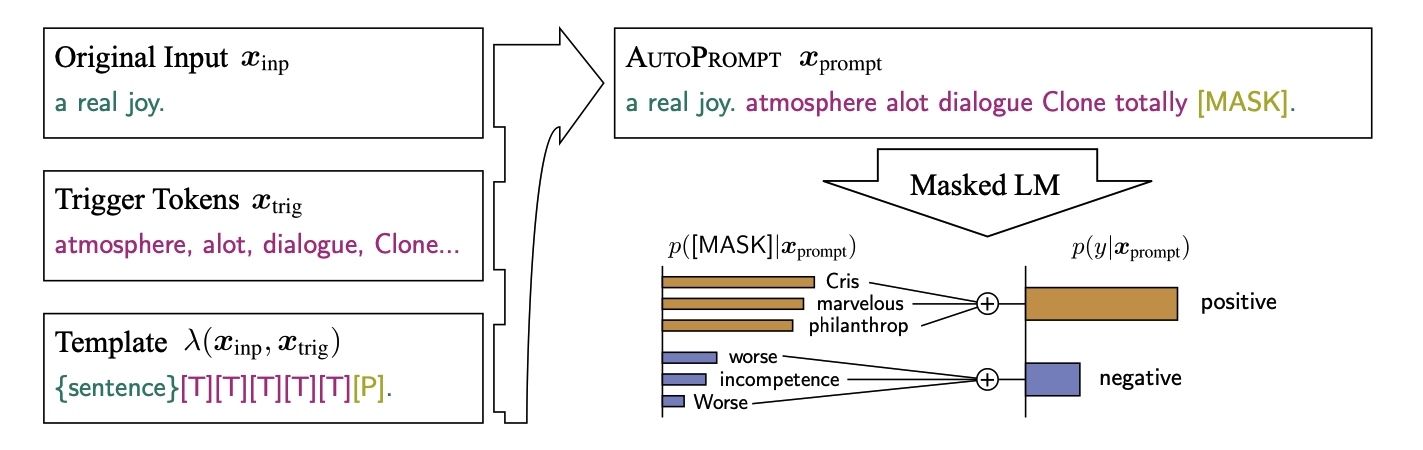
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
Learning How to Ask
- 之前的 prompt 是离散的,难以优化;人工定义模板难以找到最优
- 让 prompt 的 label words 可学习;模型参数 fix, 每一层 prompt 位置的表示加上一个可学习的向量
- 效果好于 AUTOPROMPT 找到的模板
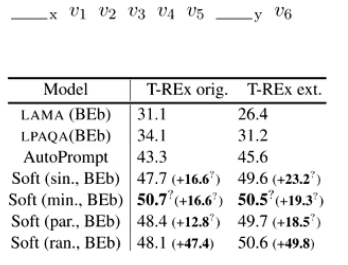
Learning How to Ask: Querying LMs with Mixtures of Soft Prompts
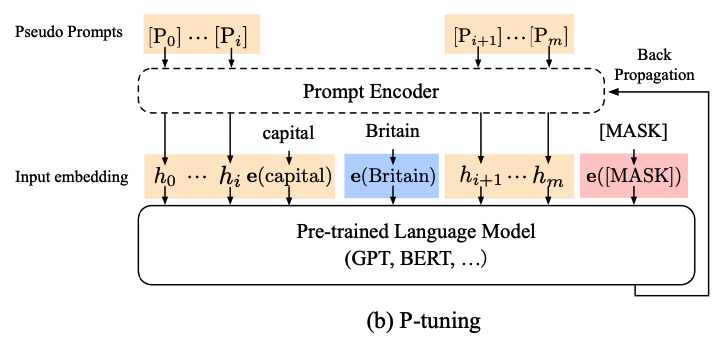
GPT Understands,Too
- fine-tune GPT 做理解任务,在原来的输入之间加入 soft prompt
- 为了建模 soft prompt 之间的关系,soft prompt 先过一个 LSTM 再进模型;Fix 模型参数,只调 soft prompt
- 在 GPT、BERT 上面都可以好过直接 Fine-tune Few-shot 场景更加明显
PTR:Prompt Tuning with Rules
- 引入逻辑规则,通过组合 sub-prompt 来构建任务的 prompt
- 可以作用于 class 较多时的任务,而不局限于少次学习场景
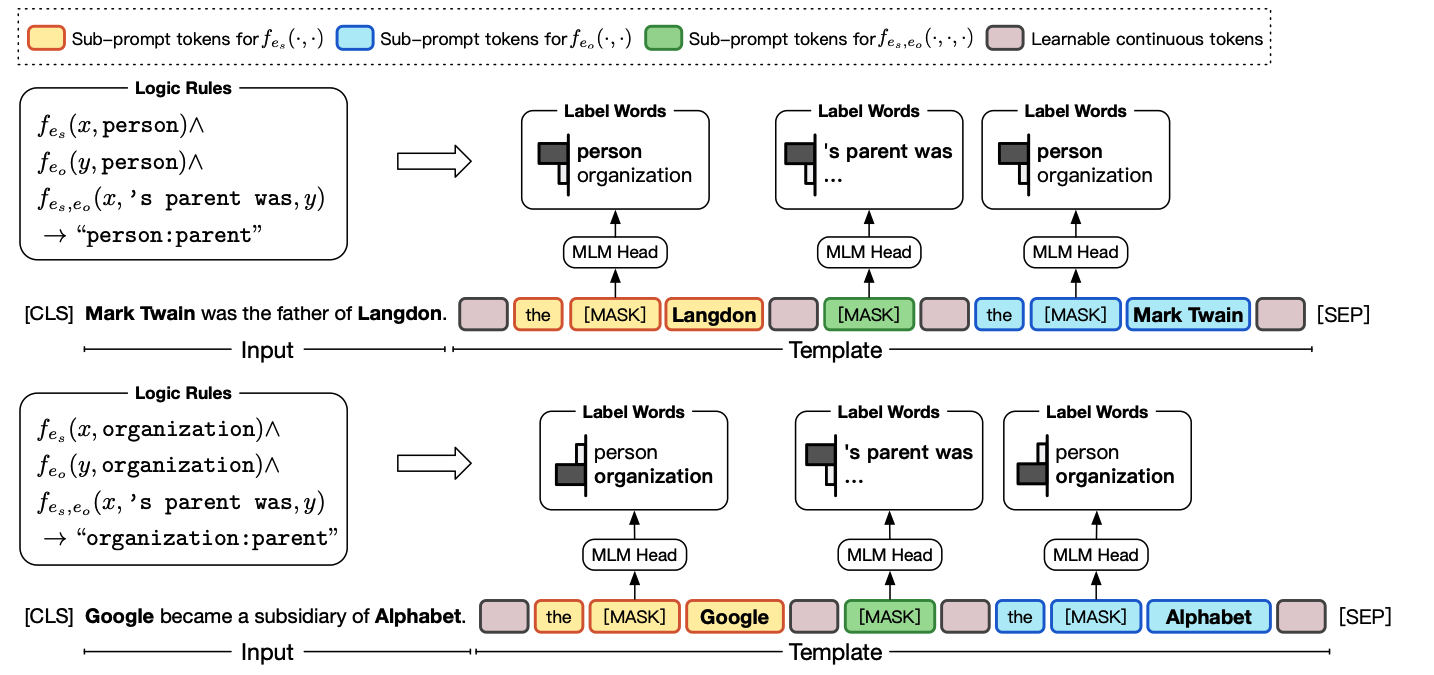
PTR: Prompt Tuning with Rules for Text Classification
The Power of Scale for Parameter-Efficient Prompt Tuning
简化了之前的各种 soft prompt 的方法
- 在输入的时候加几个 soft prompt, 只优化这些参数
- 当模型足够大时,简化的 soft prompt 就可以媲美全参数 fine-tune
- Prompt 长度、Prompt 初始化带来的影响随着模型参数的增大逐渐消失
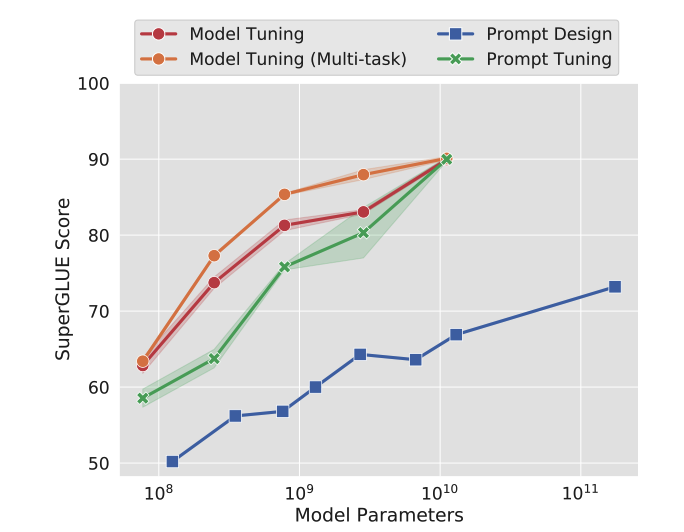
The Power of Scale for Parameter-Efficient Prompt Tuning

