让生成文本更切题,更有常识
前言
文本生成(Natural language generation,NLG)的目的是通过各种形式的语言或非语言数据,如文本数据、数字数据、图像数据、结构化知识库和知识图谱,产生人类可理解的文本。在实际场景中,生成有一些非常重要的挑战,比如:是否流畅性?、是否主题相关(可控性)?、是否符合常识?。
第一个问题随着超大规模预训练语言模型的兴起,例如GPT2/GPT3,得到部分解决。这些模型生成的句子大部分都很通顺,但是后两个问题还是待解决的难题。本次文章主要介绍在这两个问题上最新的进展。
下文的组织为,先介绍一篇控制文本生成的方法(Inverse Prompting),之后是生成融入知识相关的一篇综述,最后会具体介绍一篇预训练融入知识的方法。
Inverse Prompting
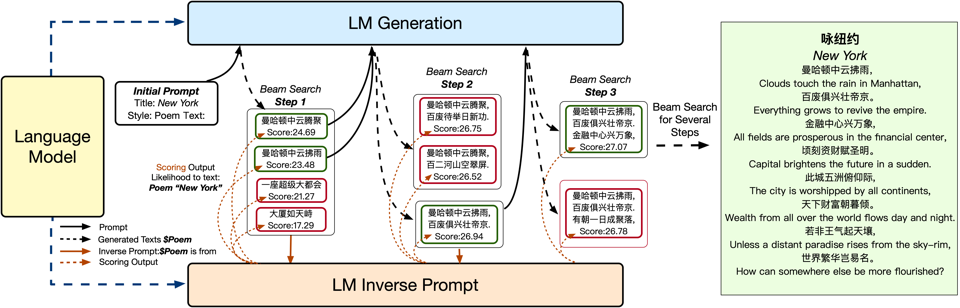
咏纽约
曼哈顿中云拂雨,百废俱兴壮帝京.
金融中心兴万象,顷刻资财赋圣明.
此城五洲俯仰际,天下财高朝暮倾.
若非王气起天壤,世界繁华岂易名.
上面这首诗是由AI创作,不知道大家读完什么感受,我其实还是蛮震惊的,尤其是最后一句“若非王气起天壤,世界繁华岂易名.”蕴意十足。
该首诗来自[1],论文提出了一种控制文本生成内容的方法(Inverse Prompting),它的核心思想是通过生成文本反过来去预测提示文本。
在正式开始前我们先介绍下prompt,当利用模型比如GPT3去生成文本时,一般都需要给一个提示词,简单讲这就是prompt。
算法细节
生成流程
我们以“输入:标题纽约,风格:诗歌”为例逐步拆解一下模型如何生成,如下图所示:
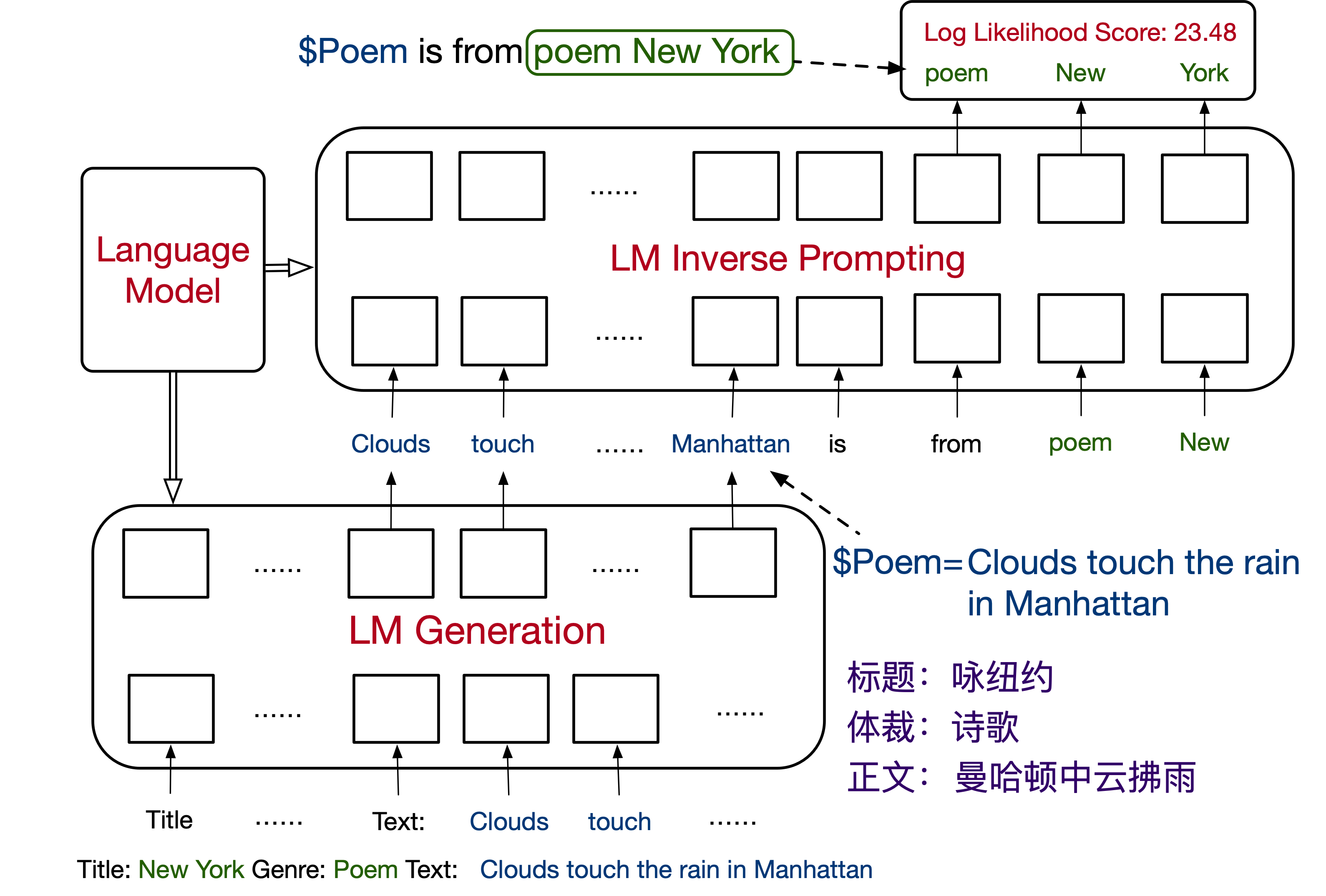
1.利用输入的标题和风格形成初始prompt,这里直接拼接就可以,比如"标题:纽约,风格:诗歌".
2.将prompt输入到语言模型中,模型利用beam search的方式生成若干个句子,比如4句话。
3.对2中的4个句子,通过打分函数可以得到每个句子的分数,并选择分数最高的句子,作为生成句子。
4.重复2~3的操作,直到完成整个诗歌。
invert prompt
这里有一个核心问题是:句子的分数究竟是如何打出来的?
在beam serach中过是通过对数似然来进行打分,即最大化概率$p\left(c_{g} \mid c_{p}\right)$,$c_g$是生成的文本,$c_p$是提供的prompt.打分函数$f(\cdot)$如:
$$f\left(c_{g} \mid c_{p}\right)=\log p\left(c_{g} \mid c_{p}\right)$$
本文提出了一种新的打分函数,作者认为如果prompt可以通过生成的结果再还原回来,说明生成的结果和prompt比较相似,因此打分函数如下:
$f\left(c_{g} \mid c_{p}\right)=\log p\left(c_{p} \mid c_{g}\right)$
但是文本反过来可能不是很通顺,因此作者使用下面表格里的模版,来把句子变得更通顺。

实验结果
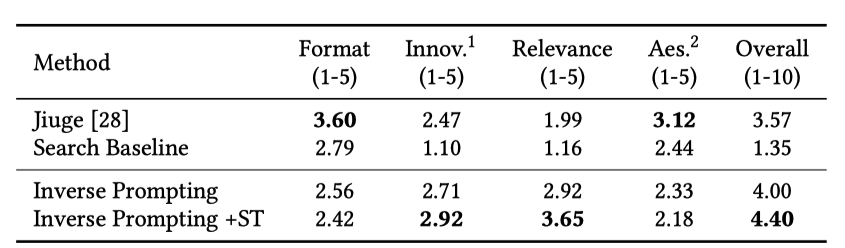
为了评估效果作者设计了5个评估指标:
- 形式(Format),生成的诗歌是否遵循中国传统诗歌的格律规则。从1分到5分评分。
- 创新(Innovation),句式是否照搬已有的诗词,或用创新的表达方式创作。评分从1分到5分。
- 关联性(Relevance) 诗歌的内容是否与给定的题目有关。评分从1分到5分。
- 审美性(Aesthetics) 诗歌除了明显的含义外,是否有隐晦的含义,使诗歌的审美性更好?从1分到5分评分。
- 整体(Overall)诗歌的整体质量。从1分到10分评分。
实验结果如下,在和Jiuge(九歌)[4]对比中,模型生成结果的关联性显著提升。
此外作者搭建了一个demo[5]来进行图灵测试,每次会从全唐诗随机抽一首古诗,然后用同样的标题AI生成一首,让人去选择哪个是人类写的。在1656次试验中,有45.2%选择了AI写的,总体而言模型非常接近人类水平,有兴趣可以去试试哈。
下面一篇是关于知识增强的综述。
Knowledge-Enhanced Text Generation
生成一般是通过用户输入的文本来进行生成,但实际中输入的文本所蕴含的信息比较有限,所以研究人员就思考如何把各种类型的知识和输入结合起来输入给模型,从而带来更多的信息,这就是知识增强的文本生成(Knowledge-Enhanced Text Generation)。
本文[7]是一篇综述,参考文献有185篇。文章首先介绍了知识的来源,然后概述了一般融入知识的方法,最后详细介绍了不同数据类型利用知识增强的具体应用。简单而言,文章主要回答了两个问题:
1.如何获取知识?
2.如何利用知识来促进文本生成?
如何获取知识
文章中列举了很多信息类型,这里解释下图四种:
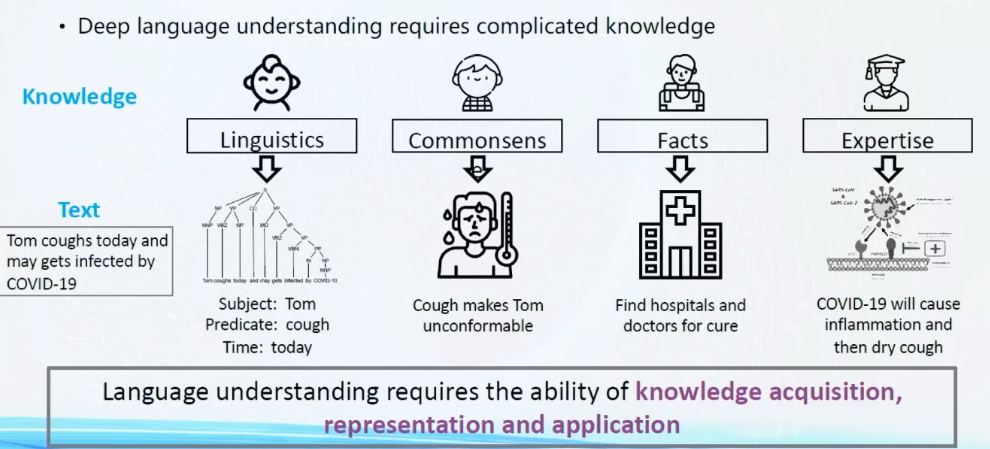
1.语言学信息: 通过句法分析、命名实体识别等、可以获得句子的语法结构和组成。
2.常识信息: 例如三元组,它可以知道发烧咳嗽会让你不舒服,同时它也知道发烧是一种病。
3.事实信息: 它当知道当你发烧时需要去医院找医生治疗。
4:专家信息: 会告诉你新冠病毒的病毒的细节,以及它让你发烧的原理。
如何利用知识
一般来说有三种途径来进行来融入知识,分别是:输入、模型结构和训练任务。
- 输入: 在输入的文本上增加一些知识,比如对句子中出现的实体,把实体描述也输给模型。
- 模型结构: 设计特定的模型结构来利用特定的知识,例如在生成下一个字符时,显式地增大实体出现的概率。
- 训练任务: 在做pretrain的时候设计一些和常识相关的任务,例如ERINE[8]在做MLM任务时会mask掉整个实体,从而让模型学习到实体的信息。
最后我们介绍一个如何在预训练引入常识的方法。
CALM
Concept-Aware Language Model (CALM)[2]是ICLR2021的一篇论文。论文提出了一种联合学习框架,可以在不依赖外部知识图谱的情况下,让模型在pretrain 时学习到更多的常识信息。
方法
论文提出的联合训练的框架如下,分为两部分:生成部分和判别部分。

生成部分
生成由两个任务组成,如下图所示。
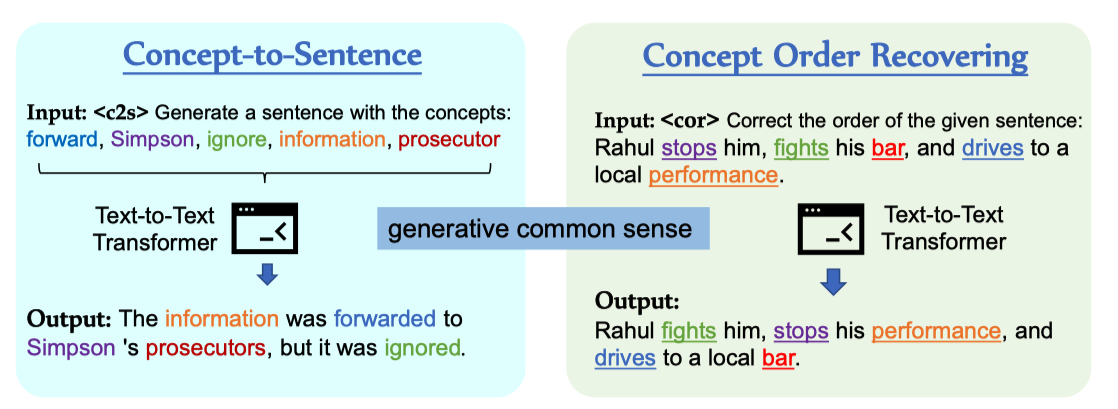
两个任务都用到 concept(概念),它的获取方法是:通过对句子进行词法标注(POS),然后选择句子中的动词、名词得到概念集合。
具体两个任务如下:
1.Concept-to-Sentence Generation (C2S):输入concepts还原整个句子。
2.Concept Order Recovering (COR):对句子中的concepts打乱,让模型还原正确的句子。
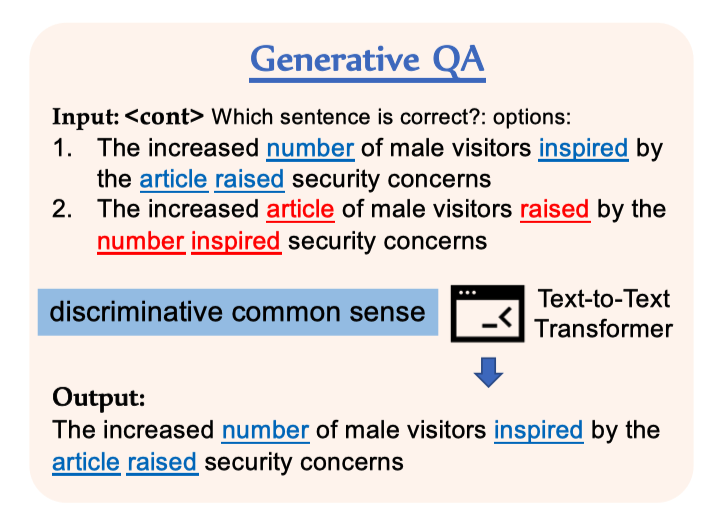
判别部分
判别模型的目标是让模型从一堆非常接近真实的句子中找到真实的句子。这些接近真实的句子是由模型生成的语法正确但是可能不符合常识的句子。具体学习方式为:同时输入真实的句子和生成句子,让模型生成真实的句子。
实验
先介绍一个数据集CommonGEN:给定一组常见的概念(例如,{狗、飞盘、接住、抛出});任务是生成一个连贯的句子,用这些概念描述一个日常场景(例如,"一个人抛出一个飞盘,他的狗接住了它")。
在CommonGEN数据集上实验结果对比如下:
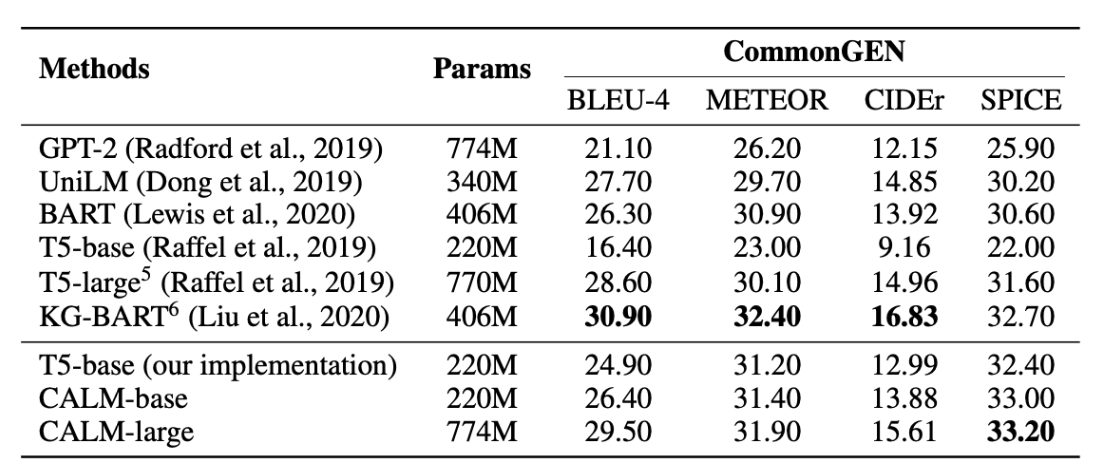
CALM打败了BART, T5-large, and GPT-2等模型,但未超过KG-BART(目前的SOTA)。作者认为比KG-BART差主要是因为KG-BERT显式使用了外部知识图谱。
总结
本文梳理了生成相关的最新进展,详细介绍了两篇paper,第一篇可以提升生成结果的切题性,第二篇则可以在预训练融入常识。并抛砖引玉地介绍了一篇最新的关于知识增强的文献综述(44页),希望可以给大家带来一些启发。
如有任何问题和建议欢迎留言讨论。
参考文献
- Controllable Generation from Pre-trained Language Models via Inverse Prompting
- Pre-training text-to-text Transfomers for concept-centric common sense,ICLR2021
- Self-training Improves Pre-training for Natural Language Understanding,NAACL2021
- Jiuge: A human-machine collaborative chinese classical poetry generation system.
- https://pretrain.aminer.cn/app/poem_turing
- https://pretrain.aminer.cn/apps/poetry.html
- A Survey of Knowledge-Enhanced Text Generation,https://arxiv.org/abs/2010.04389
- ERNIE: Enhanced Representation through Knowledge Integration


