
竞赛总结:CCL 2021 图文幽默计算
2021 年第三届幽默识别研讨会刚闭幕,本次我们取得了第二名的成绩,并在大会上作报告。本文对参赛者的方法进行汇总,按照排名从低到高的顺序进行介绍。

评测总结

任务介绍

参赛数据统计

评测数据分析
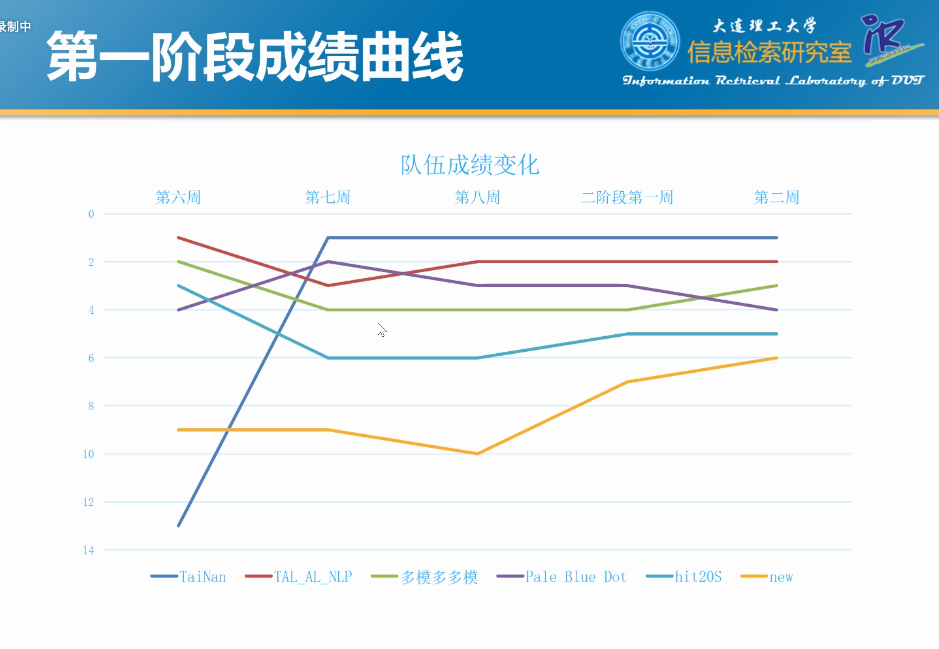
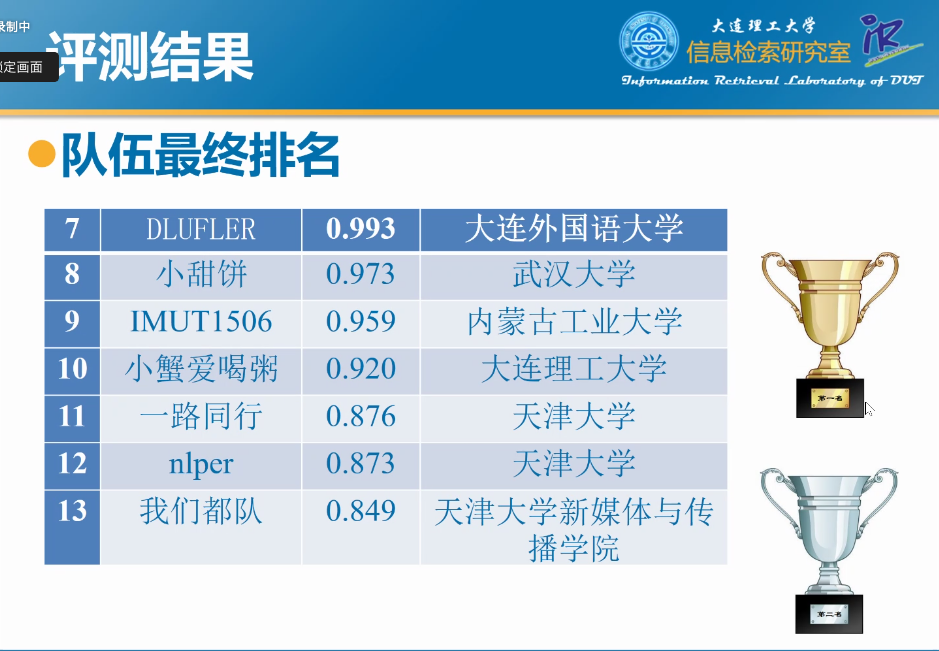
评测结果
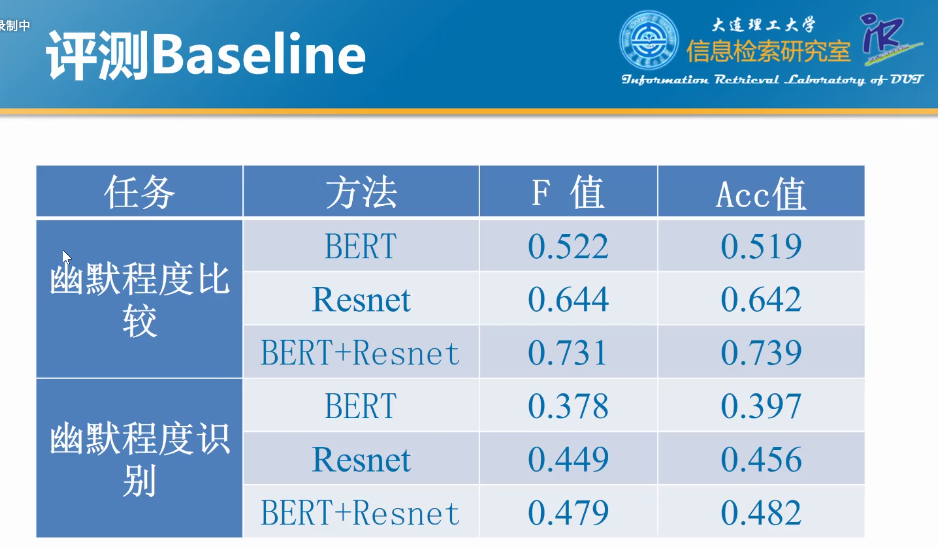
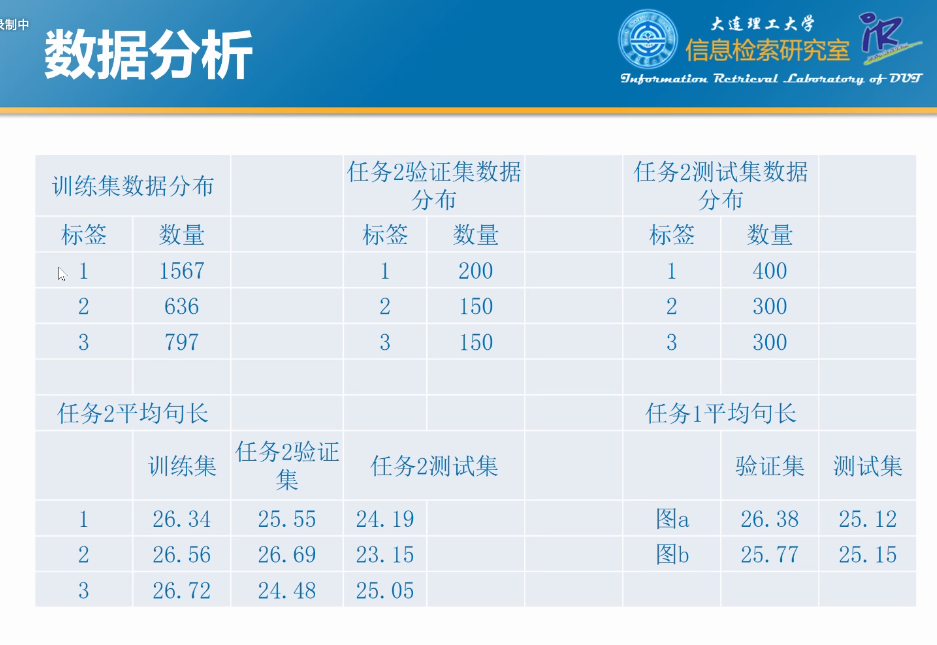

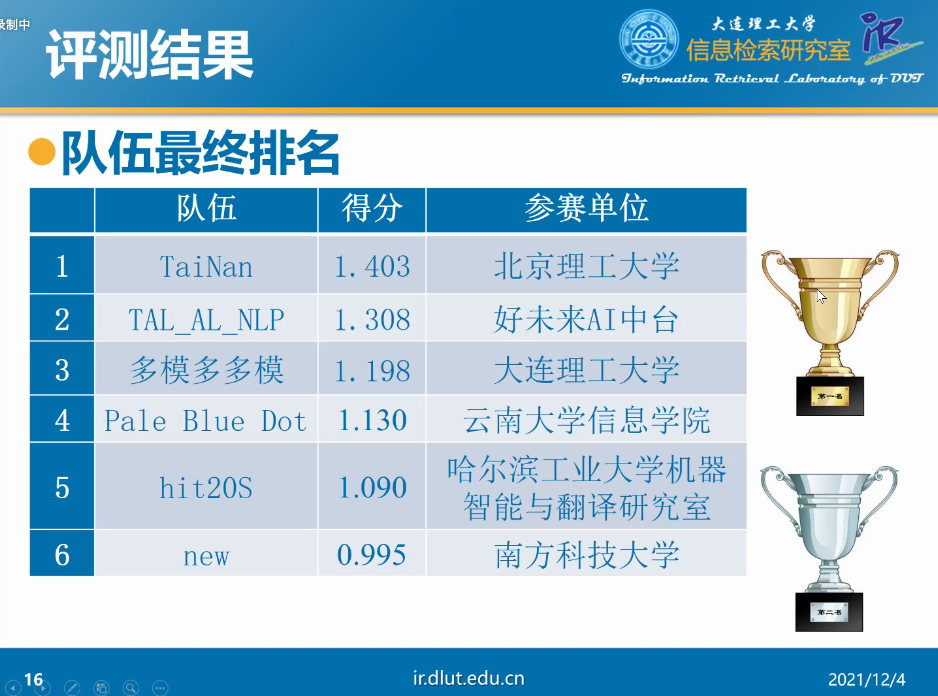
方案汇总
报告的顺序按照排名倒序排列。
报告 1. 一种基于预训练模型的多模态幽默识别方法,韩超(云南大学)

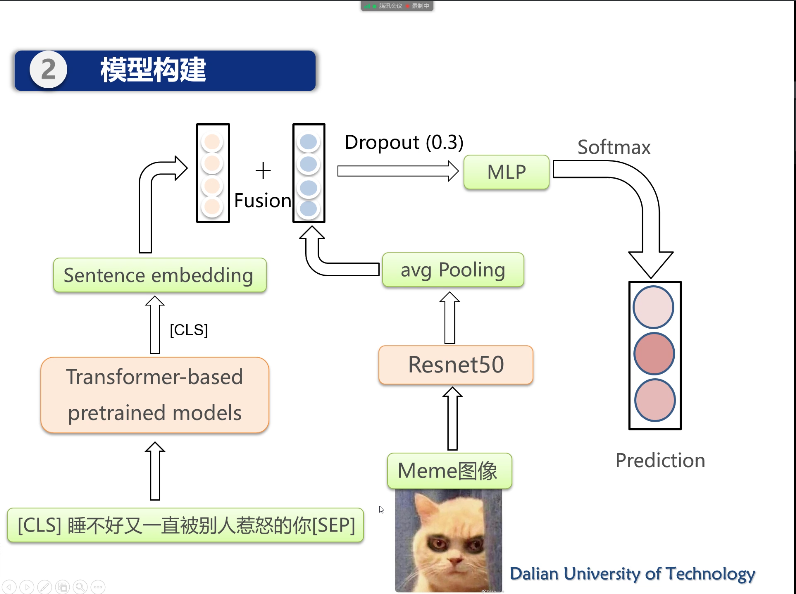
模型介绍
文本: electra
图像:vgg
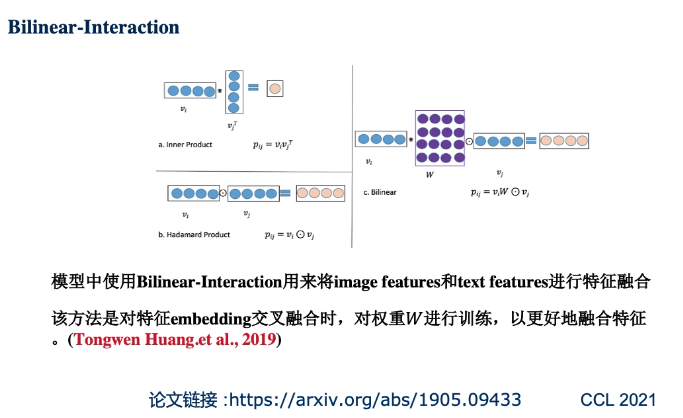
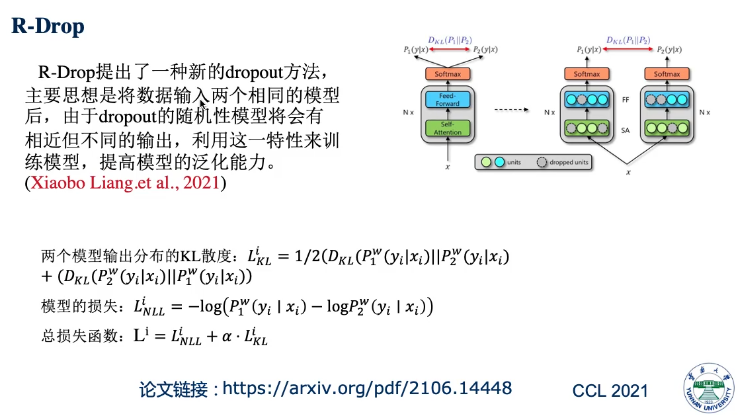

方法
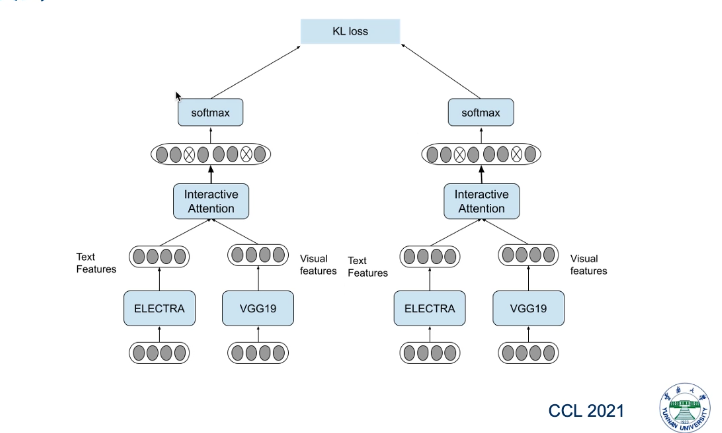
评价
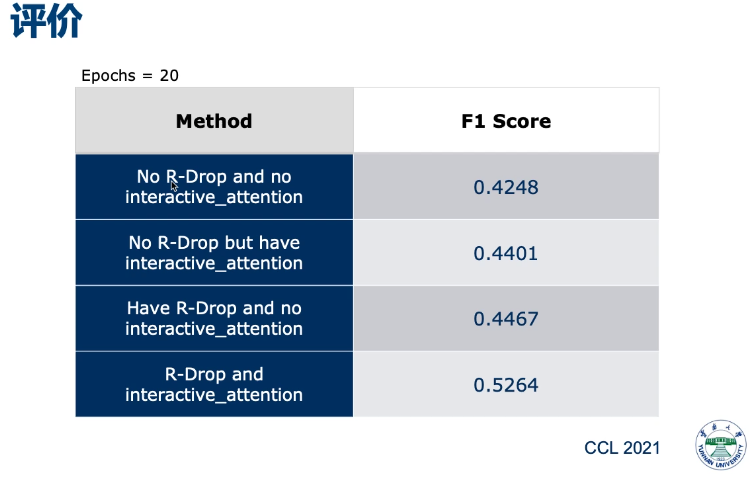
结论

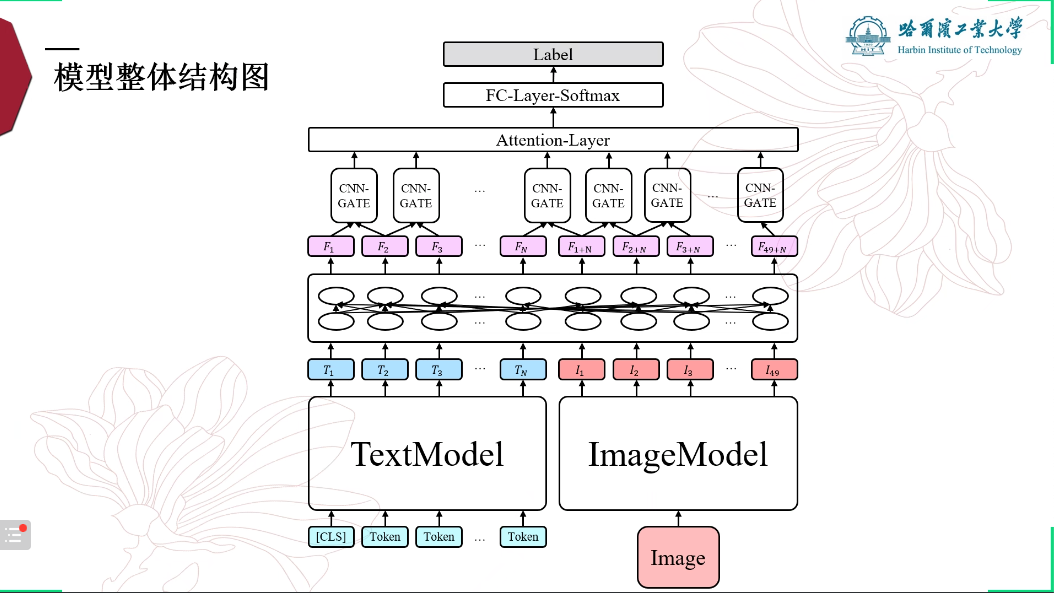
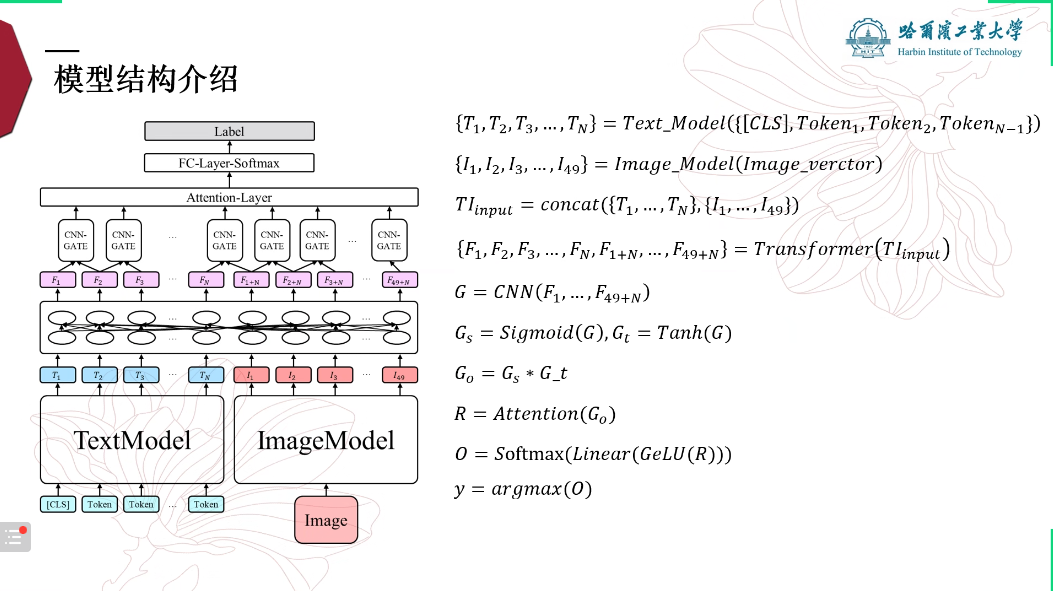
报告 2. 基于 Transformer 编码器的多模态幽默识别方法,李振(哈尔滨工业大学)

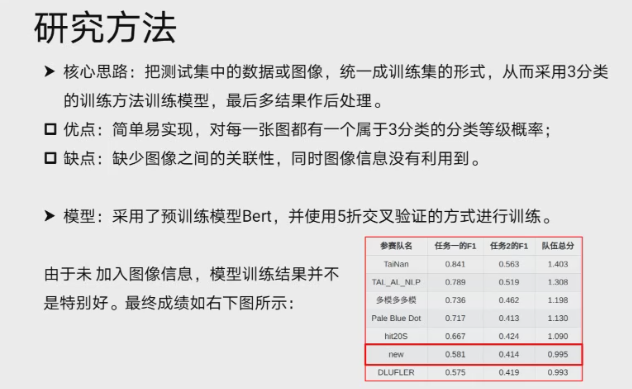
报告 3. 一种基于 Bert 模型的幽默识别方法,吴绍武(南方科技大学)



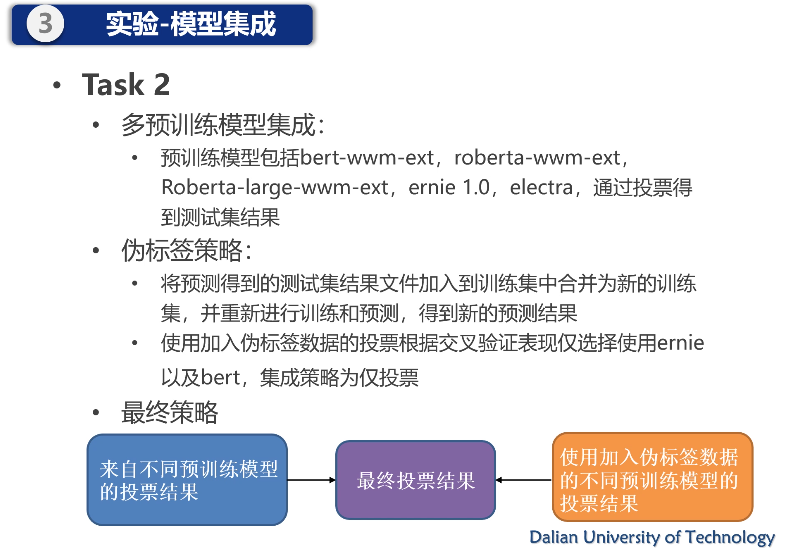
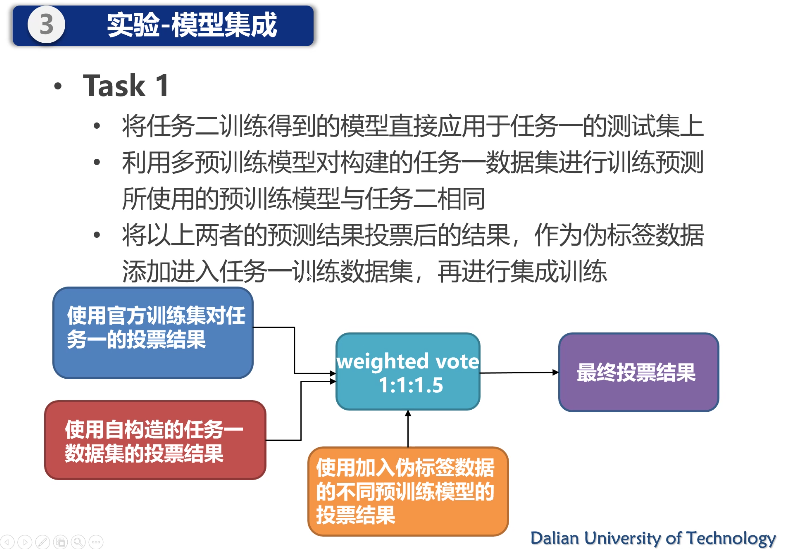
报告 4. 多预训练模型集成的数据增强图文幽默识别,耿源羚(大连理工大学)









请问可以分享下在微调和多模型集成训练时的调参技巧吗?
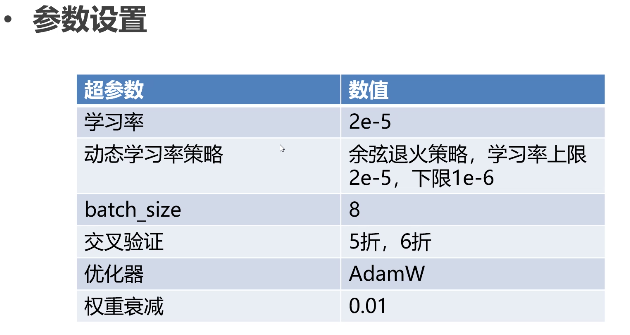
- 单个模型:调参方法,先用一个预训练开始,找到一个比较好的参照。然后再去调整,比较注重学习率,可以从极端小开始调整。权重衰减可以调整。设置步数,进行停止。
- 多个模型:更具经验值投票,手动调整模型投票的权重。
报告 5. 一种基于多模态集成学习的幽默识别方法,陈佳豪(好未来)

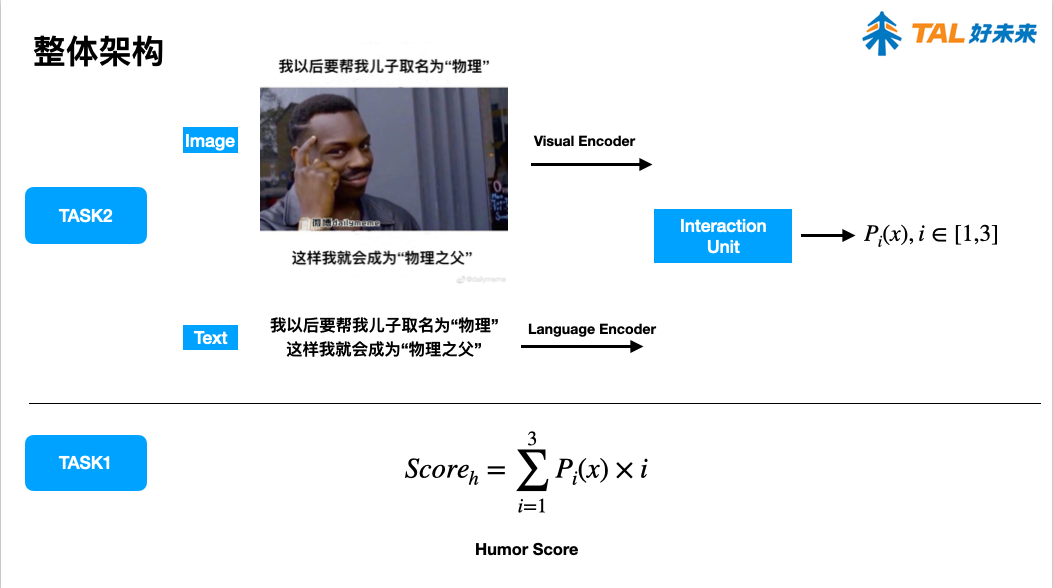
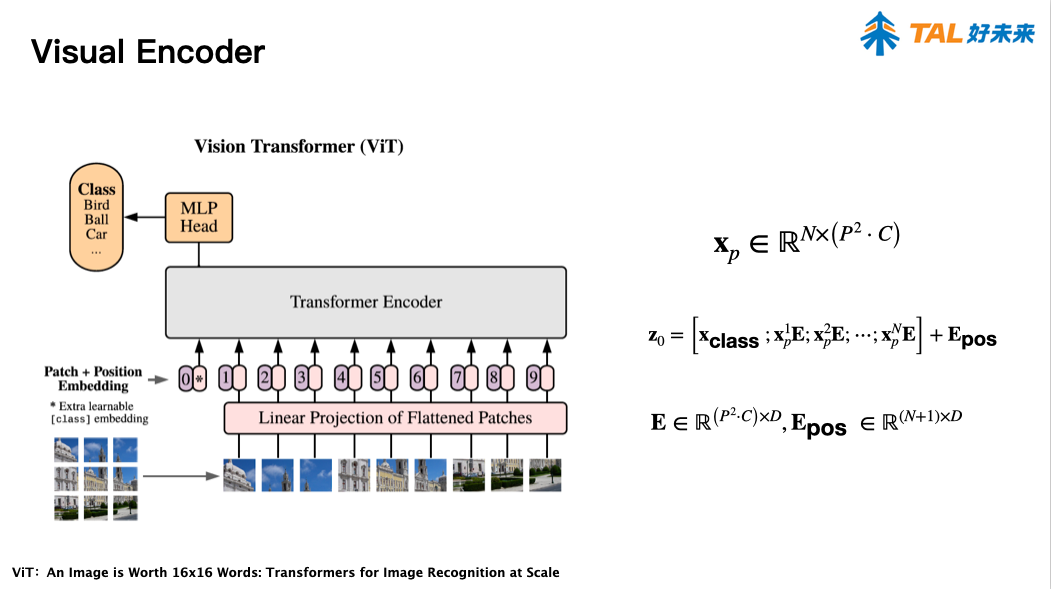
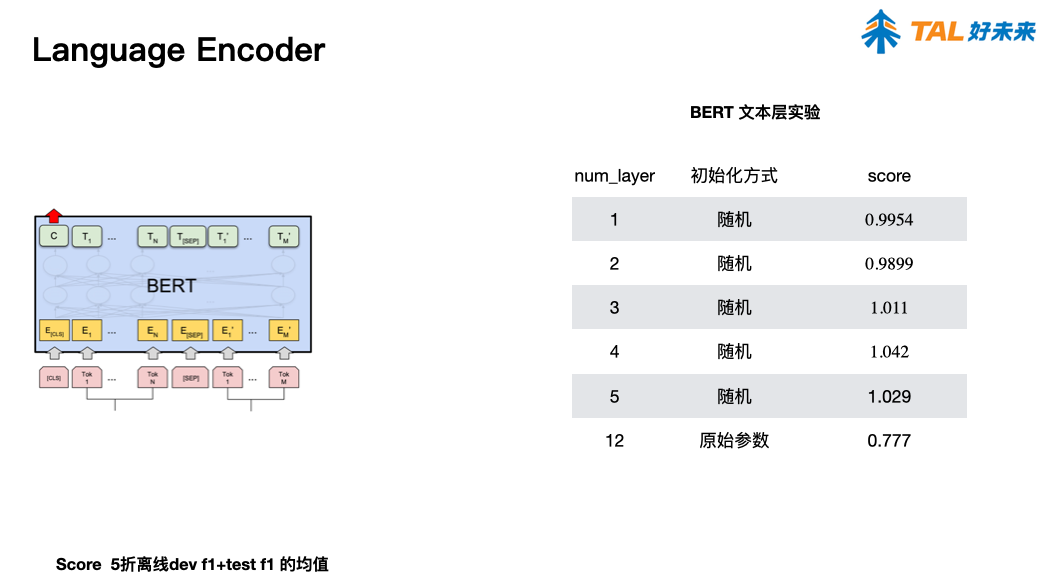
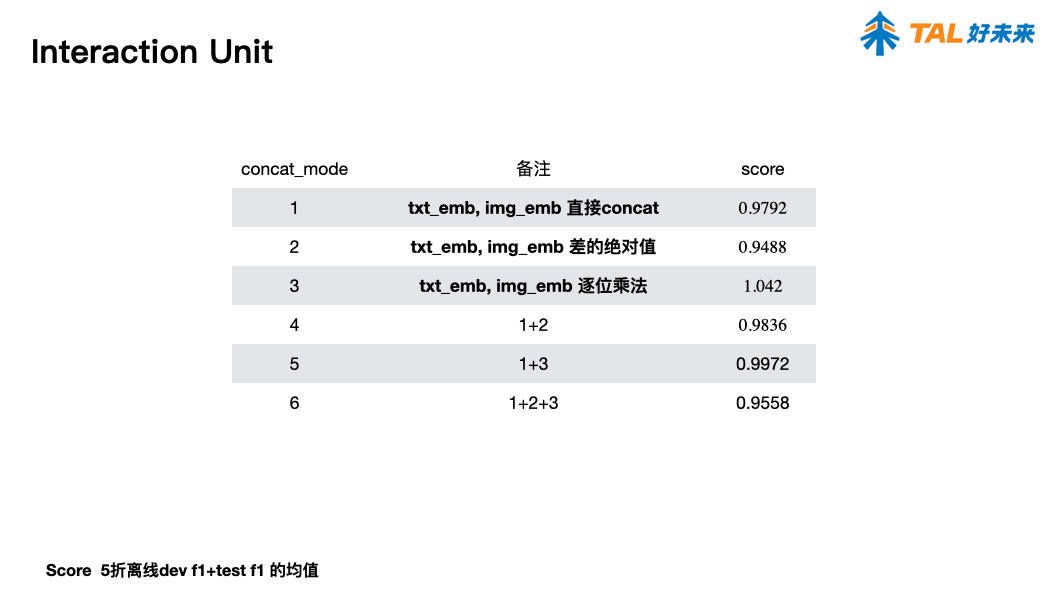
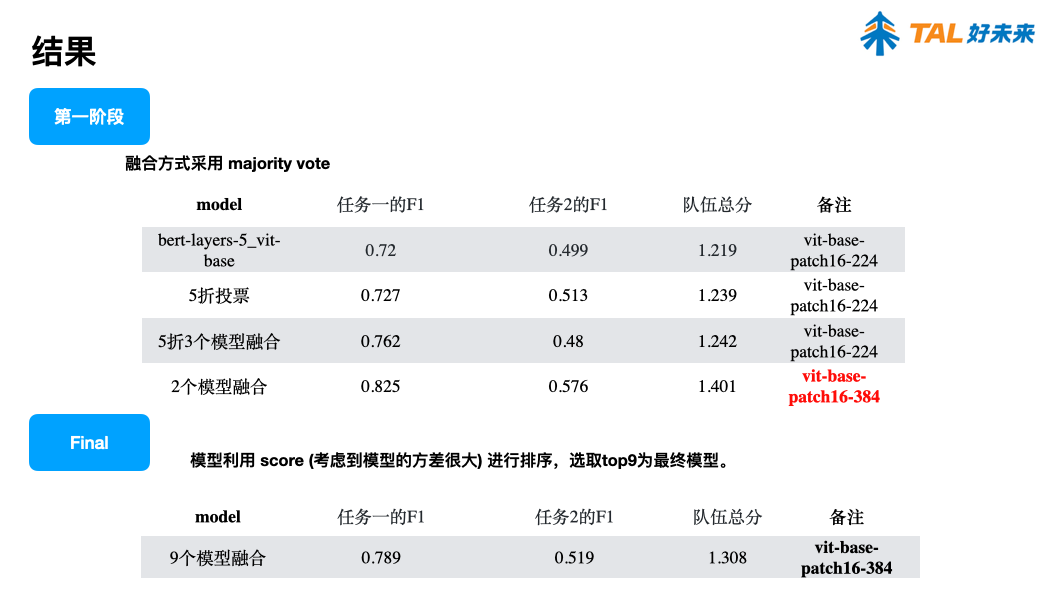
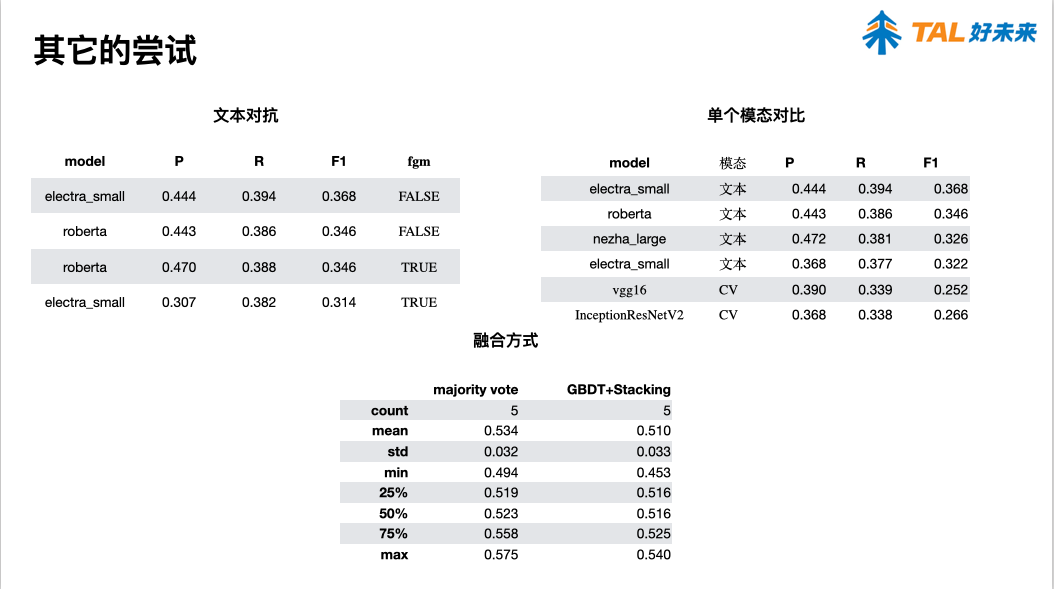
报告 6. A Simple Approach for Humor Classification on Memes using Transfer Learning,陈雨涛(北京理工大学)




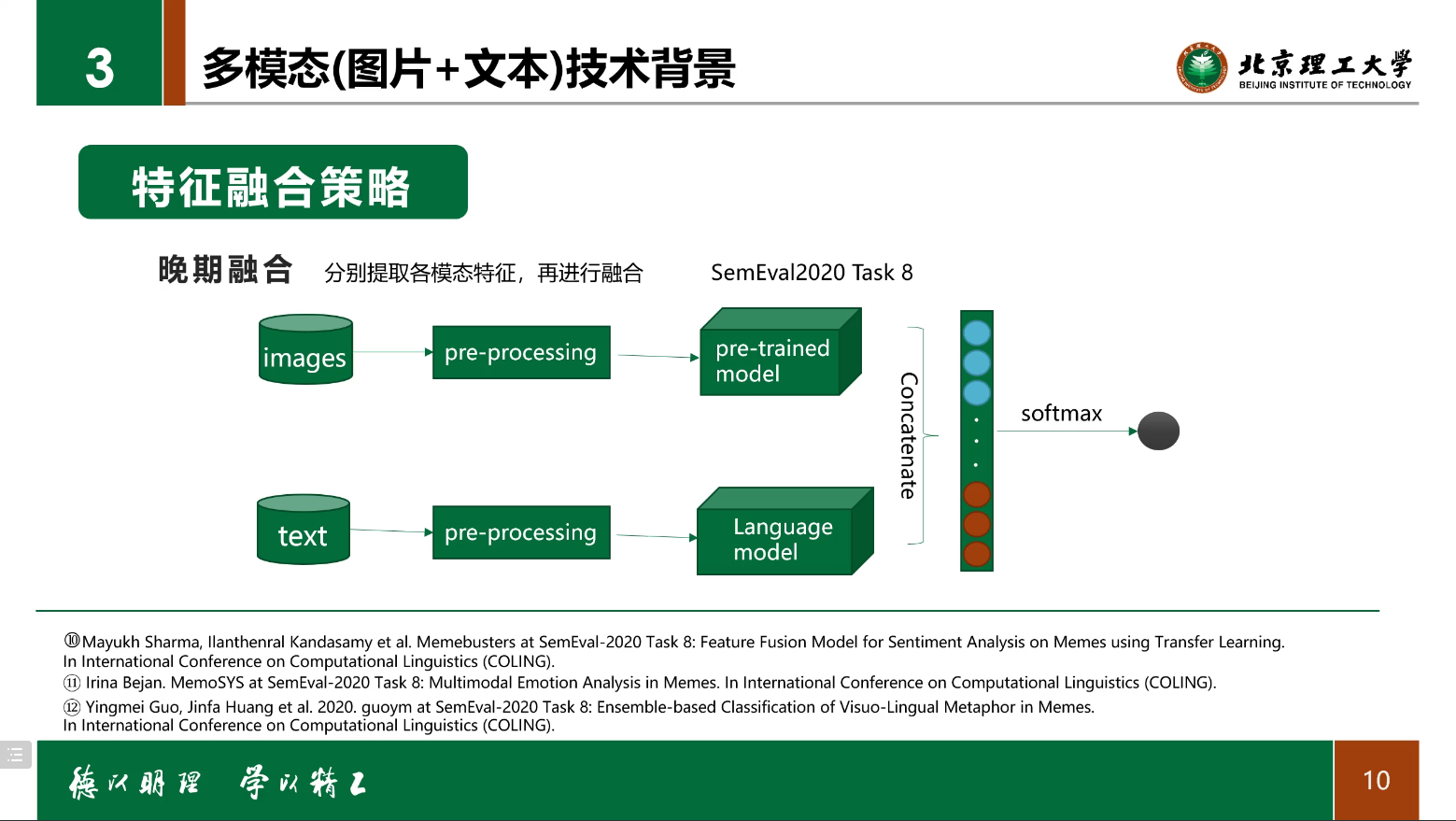
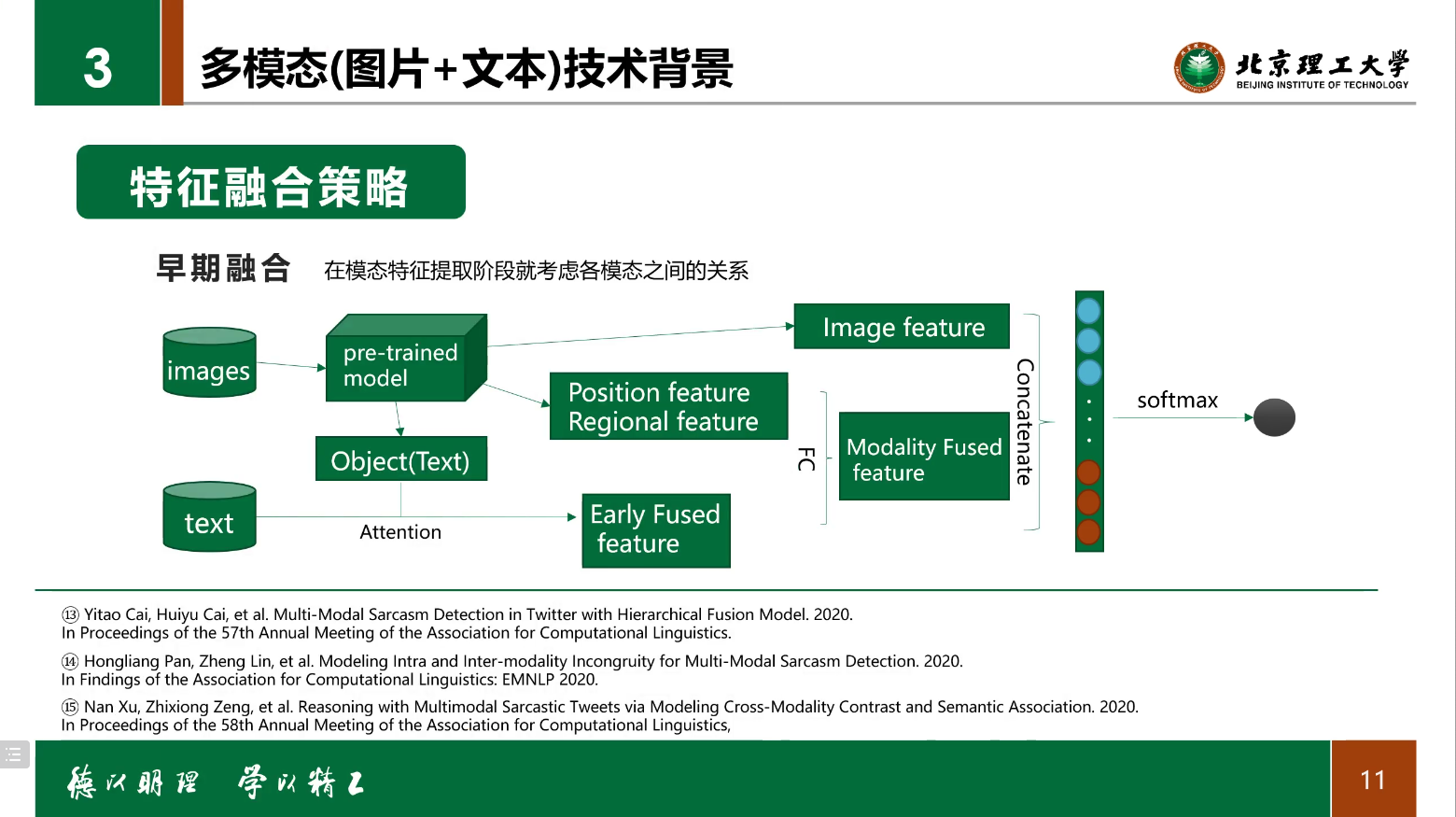

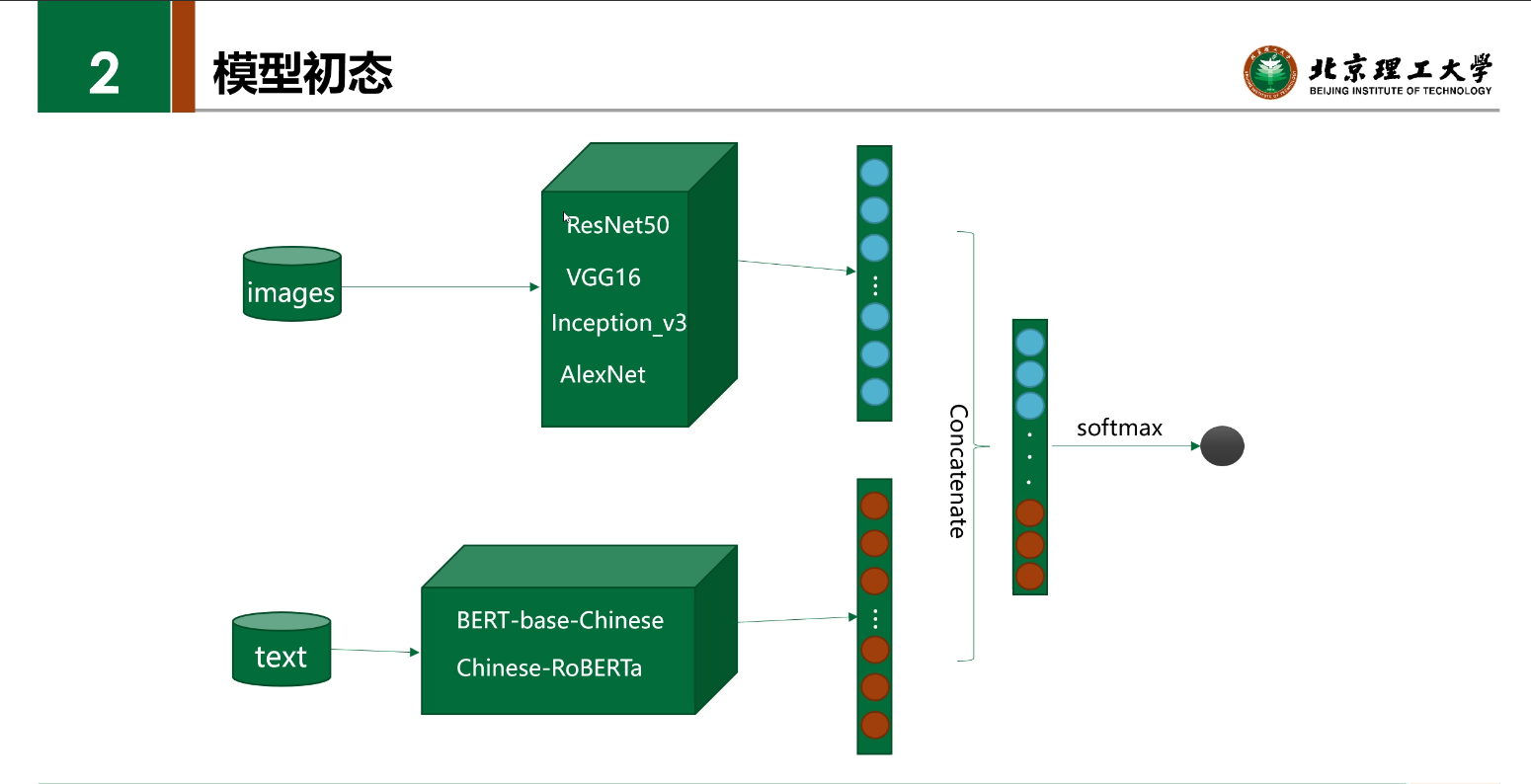
迁移学习
- 数据量少
- 各预训练模型的优异表现
晚期融合
- 数据集图片存在多种来源,Faster-RCNN/SentiBank 等无法有效提取目标对象。
- 导致图片的语义信息与文本不在同一空间。

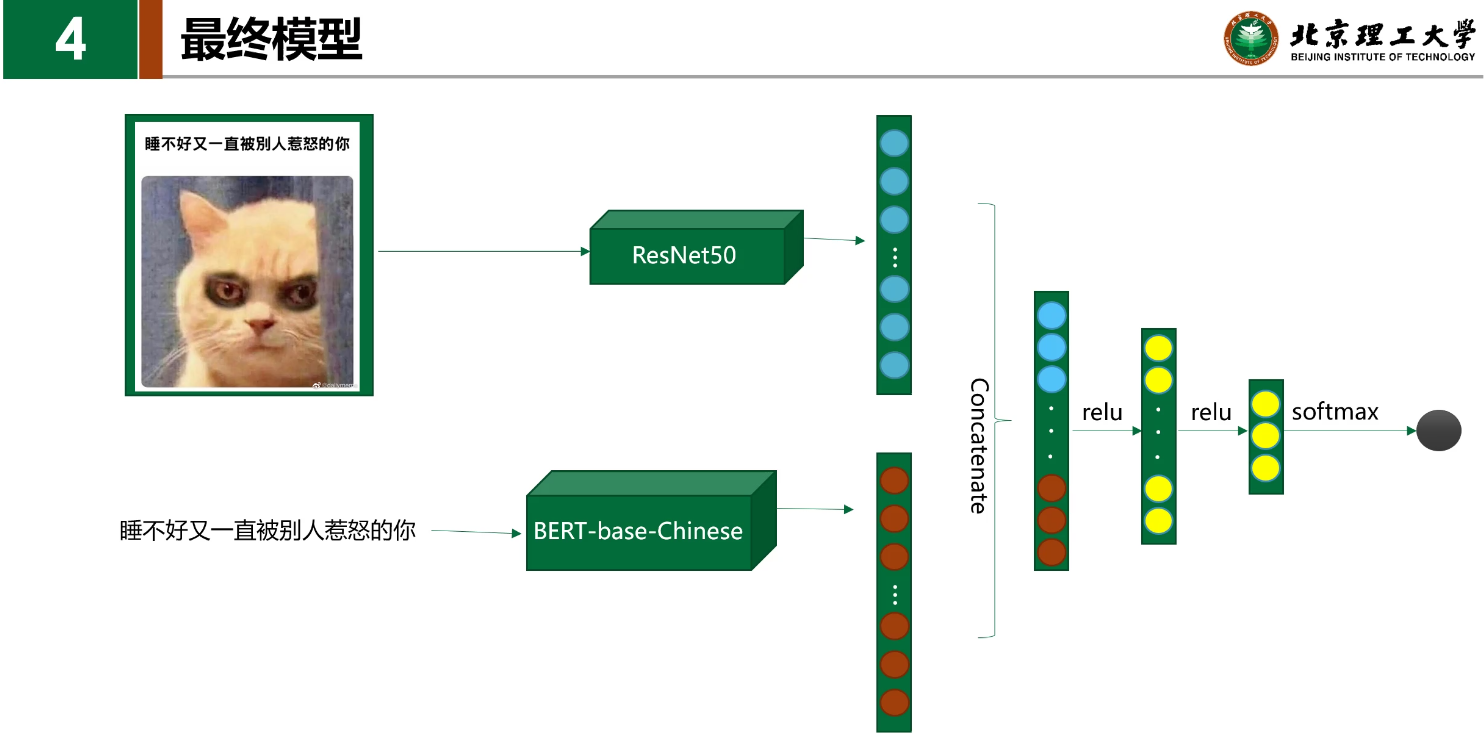
完全相信模型


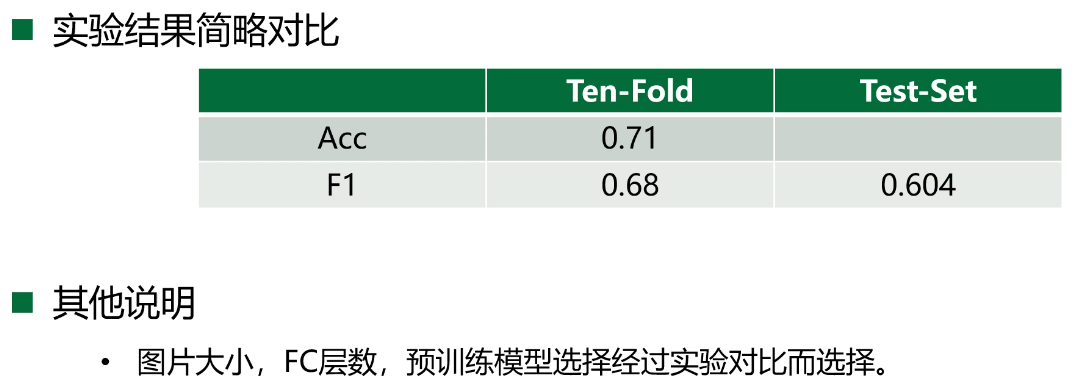

总结那些有效?
- 从图片提取文本,会好一些
- 图片的大小以及后面非同质的问题,对结果影响比较大

