
2020 中国计算语言学大会幽默计算评测冠军方案
前言
机器学习团队获得中国计算语言学大会(CCL 2020)幽默计算评测第一名!CCL是中国国内NLP的两大盛会之一,由中国中文信息学会(国家一级学会)主办。比赛的场景是多轮对话中的幽默识别,和GodEye处理的问题非常类似,GodEye中是发现对话中的流利程度、情感程度、互动程度等。我们利用GodEye的算法学习框架取得冠军,并受邀在CCL2020上作技术报告。
比赛证书

本文算是对此次经历的一次复盘和总结,同时也期望能对大家在解决工作的问题有所帮助。
比赛概述
本次比赛属于国内NLP盛会(CCL)的一个评测任务。CCL是中国计算语言学大会,是中国国内NLP的两大盛会之一。背后组织方是,中国中文信息学会,中国一级学会。
幽默是一种特殊的语言表达方式,在日常生活中扮演着化解尴尬、活跃气氛、促进交流的重要角色。而幽默计算是近年来自然语言处理领域的新兴热点之一,其主要研究如何基于计算机技术对幽默进行识别、分类与生成,具有重要的理论和应用价值。
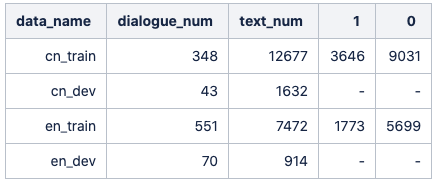
本次评测任务的数据涉及两种语言:英文数据来自情景喜剧《老友记》,中文数据来自情景喜剧《我爱我家》。任务根据场景变换将情景剧的对话结构分为Dialogue和Utterance两个层级,其中一个Dialogue包含若干个有序出现的Utterance。每个Utterance存在幽默标签,标签“0”表示非幽默,“1”表示幽默。
如下图是数据的示例
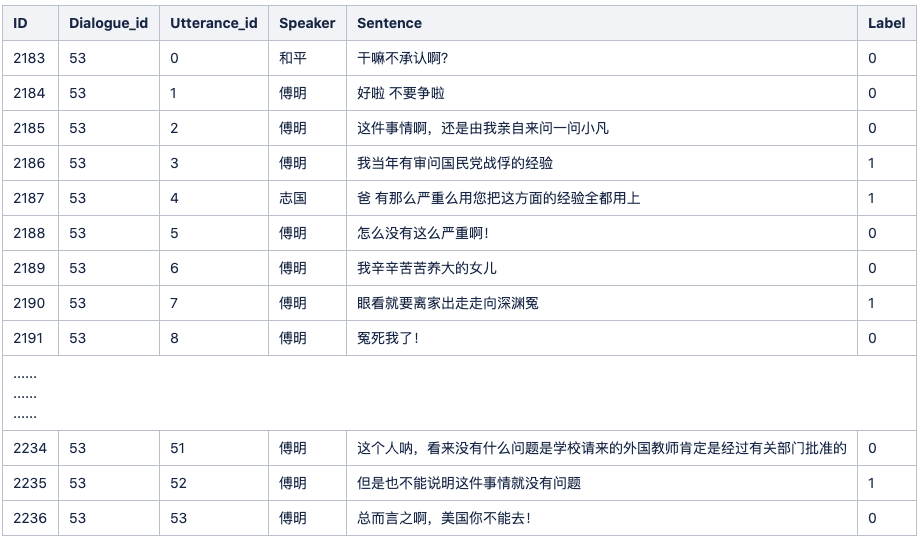
数据的分布情况如下
评价指标
结合本次评测任务的特点,采用以下评价指标进行评价:
1.Utterance级评价指标:
参赛者需要预测每个Utterance的幽默标签,即幽默(label=1)、非幽默(label=0)。该级别评价可视为二分类任务,采用F1值进行评价。
2.Dialogue级评价指标:
由于每个Dialogue长短(包含的Utterance个数)不同,参赛者的模型需要对不同长度的对话中的标签都能进行有效的预测。因此,Dialogue级别使用精确率进行评价。即首先计算每个Dialogue的精确率,再对所有Dialogue计算均值得到该级别评价指标。具体公式如下:
$$
\text {Accuracyavg}=\frac{1}{n} \sum_{i=1}^{n} \text {Accuracy}_{i}
$$
最终得分:
参赛队伍的最终得分由上述两个指标综合决定。
$$
\text {Score}=F_{1}+\text {Accuracy}_{\text {avg}}
$$
本次比赛的难点
在我看来本次比赛有4大难点。
1、多语言:本次比赛涉及两种语言,这意味着需要算法足够鲁棒可以兼容不同的语种。
2、双指标:除了Utterance级评价指标还增加了Dialogue级评价指标,这则需要对不同长度的对话中的标签都能进行有效的预测。
3、低反馈:不像一般比赛有一个实时更新的排行榜,本次比赛必须通过发邮件,且一周只能提交一次结果,每周一同步上周提交的结果。这就需要我们对自己算法要足够有信息,即需要更严格的离线验证。
4、任务难:我们只能通过文本去判断是否幽默,但在情景剧句中幽默可能和演员的语调、动作、表情等相关,如果有这些信息效果可能会更好。
前3个难点可以通过模型来尝试解决,第4个则需要引入更多维度的数据。下面介绍一下我们是如何做本次比赛的。
技术路线
整体方案
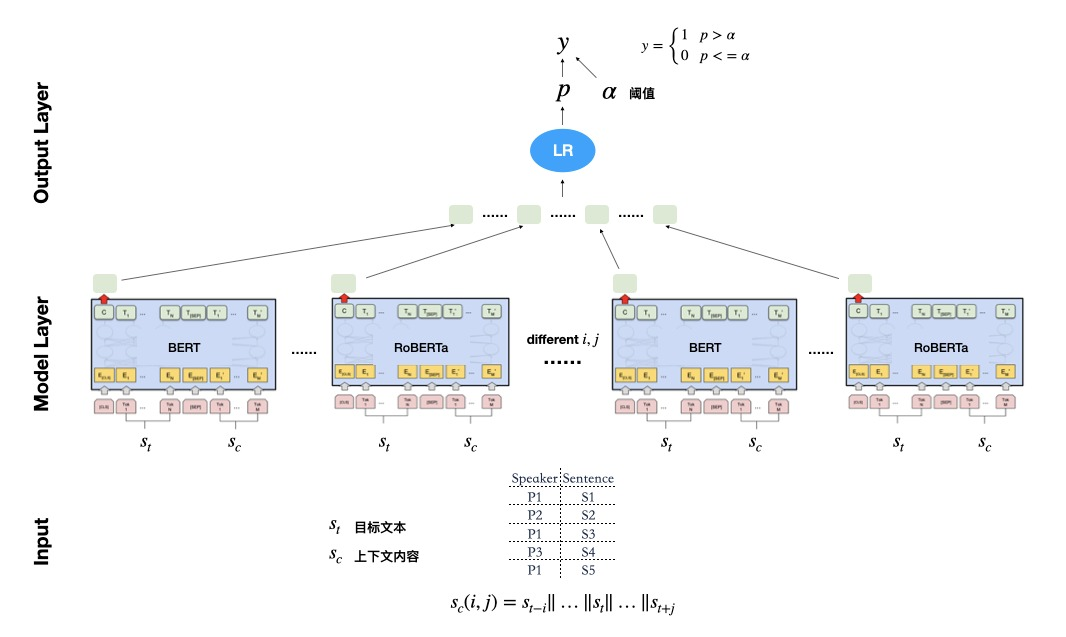
整体方案分为3层:Input、Model Layer、Output Layer。
其中Input会对一段话进行预处理,即对每一句话引入说话人和上下文信息(由两个参数控制),然后输入到Model Layer进行学习,Model Layer会使用ATC工具尝试不同的模型,并输出样本概率,之后将多个模型结果输入LR模型得到最终的概率。Output Layer会利用参数α来得到具体的标签。
下面以时间顺序介绍具体探索过程。
前期探索
数据划分
基于之前的经验我们采用基于 Dialogue_id 对进行数据划分的方法,即先将 Dialogue_id 分成 train、dev、test 三个集合,然后得到整体数据的划分,如果不这么做可能会出现非常严重的过拟合,尤其在“低反馈”的情况下可能会走很多弯路。
技术路线探索
大致有两个技术方向:
- 基于单句文本分类。
- 编码单句内容,然后使用序列模型。例如使用LSTM得到Dialogue_id中每一句的的表示,然后使用序列模型建模输出结果。
在实验中方向2效果都不太好,甚至低于单句分类,因此我们主要聚焦在技术路线1。
数据处理探索
对于技术路线1,单句分类分类,最重要就是如何进行更有效的预处理。拆分成两个问题就是:
1、如何引入说话人信息
2、如何更好利用上下文信息
我们以下图画红线的为例:
问题1:如何引入说话人信息
利用"说话人:内容"进行转换,在上面截图的例子就是,“傅明:这件事情啊,还是由我亲自来问一问小凡”
问题2:如何更好利用上下文信息
1、x-1_x_x+1
通过“x-1_x_x+1”变换得到新的句子,在上面截图的例子就是,“好啦 不要争啦_这件事情啊,还是由我亲自来问一问小凡_我当年有审问国民党战俘的经验”
2、句对
首先对每个句子引入说话人信息,然后通过"目标句[SEP]上下文"转换。上下文我们首先尝试使用从目标句上面的5句话到下2句话,以“|”拼接到一起,并截取300字符。
下图是以上方法在中文的离线数据测试结果,这里模型使用了nezha_base,可以发现引入说话人信息和上下文信息显著提高了效果。

句对上下文区间搜索
上面结果显示“句对”是最好的方法,不过其中“上下文”的编码方法不一定是最好的方法,于是我们设定两个参数up_num、down_num分别表示向上和向下看多少句。
在小数据上利用小模型(ALBERT)进行搜索,同时为了保证可信性,我们使用了5个不同的随机种子初始化模型。具体而言中文一共180组实验(up_num=5、down_num=5)
下面分别是分数的均值和标准差(std)
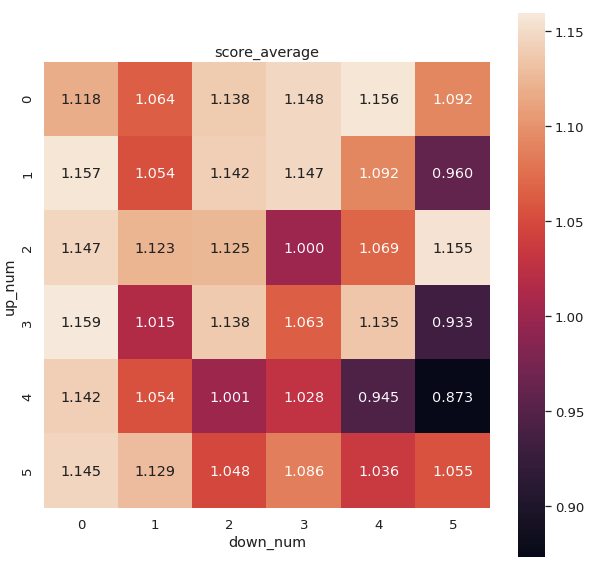
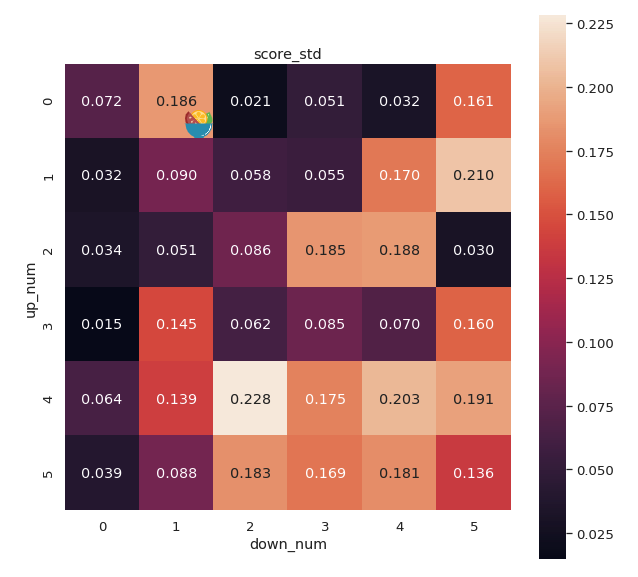
可以看到不同的参数差别还是非常大,可能受样本较少的影响有些参数的标准差也非常大。
基础模型探索
数据定了下一步就是定模型了,这里我把模型大致分成三类。
1、传统模型 : 例如gbdt、LSTM、fasttext,等。
2、预训练公开模型+finetuning : 例如bert、nezha、roberta等。
3、预训练公开模型+目标领域 pretrian+finetuning
为了简单起见,数据使用原始未处理的数据,在由ML Team开发的工具ATC(自动文本分类器)的助力下,一晚上就跑出了16个不同模型的对比结果。如下图是中文场景的结果。
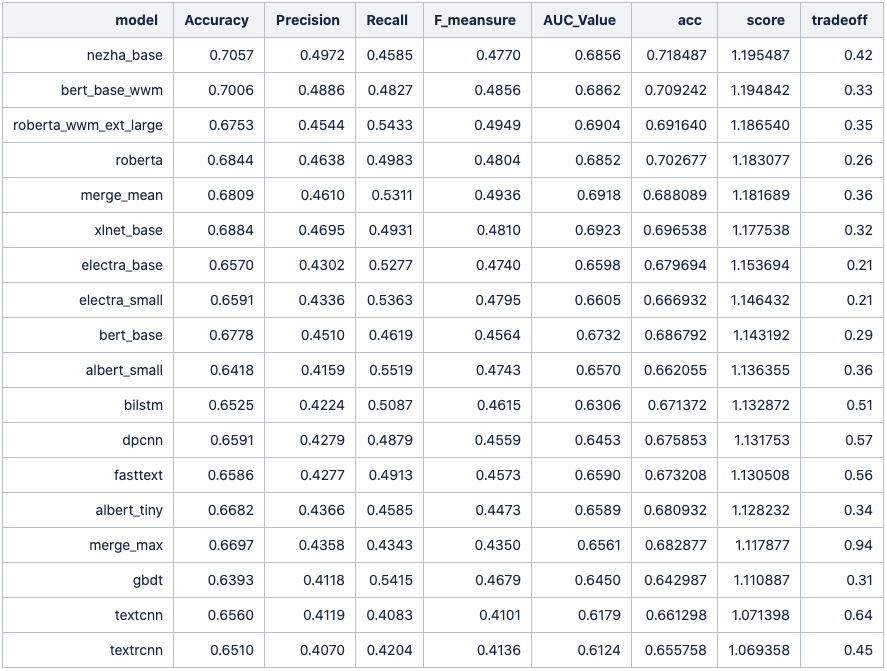
可以发现方法1效果显著低于方法2;
对于第3类模型,一般来讲如果目标领域和公开模型使用的训练数据分布差异越大那提升效果较为明显,在GodEye中我们很多分类是基于ASR文本,我们发现方法3会比方法2有较大的性能提升。
不过在本次比赛第3类则效果略低于第2类,可能是由于比赛的语料和公开模型使用的训练数据分布较详相近。
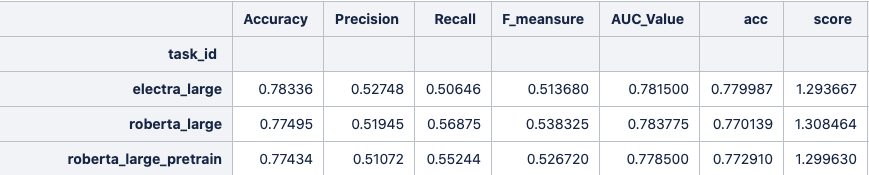
上图roberta_large、roberta_large_pretrain分别代表第2类和第3类,看score这列可以发现后者略低一点。
综上我们以后均适用第二类模型。
最终模型
经过以上的尝试,我们最终的模型如下图所示,一共分为三个阶段
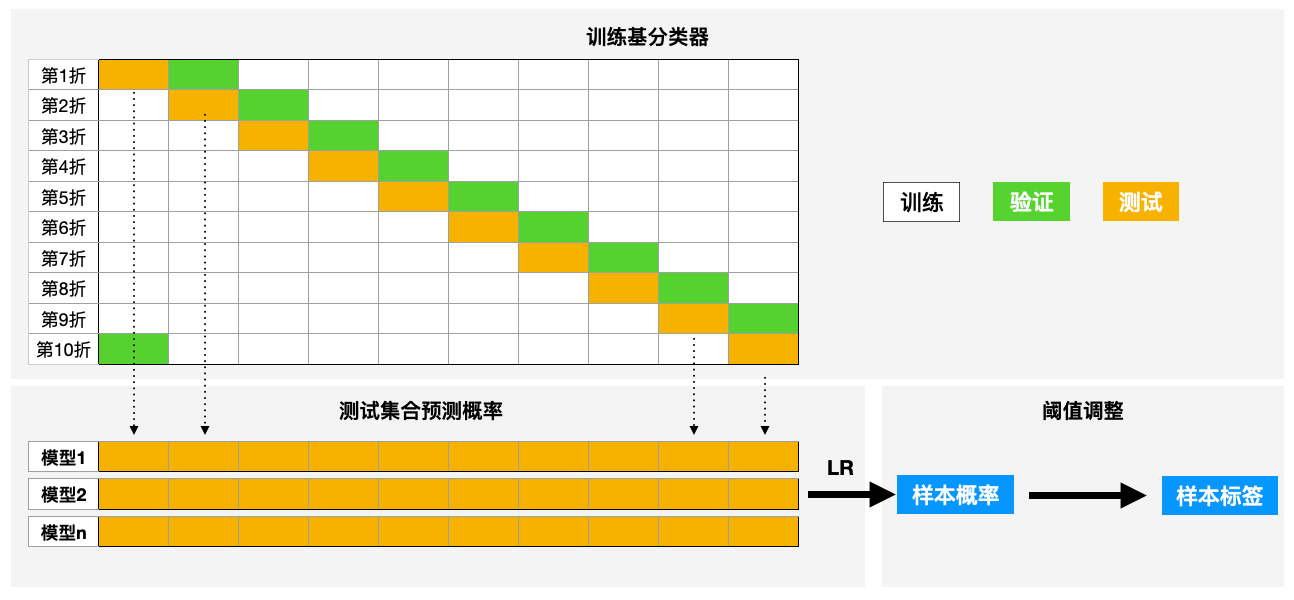
第一阶段:训练基分类器
数据划分为10折,其中1折为dev一折为test,在8折训练用同参数训练基分类器,在dev上使用early stop机制。然后用训练好的模型预测test得到概率。10折跑完一轮则可以得到由test构成的和原始数据一样的数据。以此当作特征。
第二阶段:stacking
选取阈值:同样10折,按照第一阶段一样划分,使用train+dev训练LR模型,预测test,并调整不同阈值得到不同阈值结果。一轮后,得到不同阈值下LR的表现,取分数最高的当作最终的阈值令为p。
用全部数据训练最终LR模型:以第一阶段得到的特征为输入,训练LR模型。并预测最终测试数据得到概率。
第三阶段:阈值调整
使用阶段二得到的阈值p来得到最终的标签。
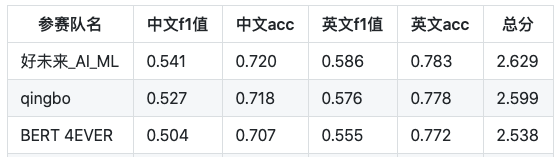
结果展示
思考和反思
1、前期多做实验,用数据和指标说话。 很多直觉认为work的方法可能不是很好。对一些非常重要的参数可以在小数据上进行搜索。
2、做好CV(交叉验证),然后相信自己的本地测试数据,公榜只做参考。 本次比赛期间就出现本地高了但是线上低了,加之“低反馈”我们也很难及时调整。在决定最终提交模型时,我们选择相信自己本地的结果,提交了本地最好的模型。
3、关注数据分布。在样本不均衡或者指标和训练模型的指标不一致,要记得阈值调整或者针对指标优化。可以看到上面实验我们阈值很少是0.5,此外记住在调整阈值要遵循CV(交叉验证)的原则,不然可能过拟合。
4、平时构建好工具,增强复用能力。 例如本次比赛中,由 ML Team开发的ATC(自动文本分类器),发挥了至关重要的作用!该工具目前支持所有文本分类任务,可以一键运行34个模型和10+词向量。目前ML组全员使用,也在积极推动内部开源,开源后续大家可以进行尝试。
致谢
本次比赛队伍成员有:陈佳豪、郝洋、向宇、丁文彪、刘子韬。非常感谢各位老师和伙伴的指导和支持。同时ML Team的其它伙伴也给出了不少建议,再次谢谢各位伙伴,冠军属于ML Team。
参考文献
[1] 比赛介绍,http://cips-cl.org/static/CCL2020/humorcomputation.html
[2] 比赛结果链接,https://github.com/DUTIR-Emotion-Group/CCL2020-Humor-Computation

